
1. Introduction
Malware detection has made a significant progress recently with multimodal approaches as one of the promising emerging paradigms. These approaches fuse tabular, image-based, and sequential features to optimise detection accuracy and generalization. Image-based techniques which convert executable files into greyscale images or other visual representations, capture structural patterns without the need for reverse engineering. Methods such as grayscale or byteplot images have demonstrated high accuracy in classifying both adversarial, obfuscated and normal malware by leveraging intensity patterns and visual textures that are inherently less sensitive to conventional obfuscation and adversarial techniques [1, 2]. Tabular representations, including metadata, system call sequences, and bytecode semantics add to visual features by providing rich static and dynamic behavioural information where these features are often modelled using graph-based models or deep learning architectures to capture semantic relationships and dependencies [3, 4]. Integrating diverse modalities allows malware detectors to exploit complementary feature spaces to achieve a level of insight and resilience that unimodal systems cannot provide.
Notwithstanding, the increasing complexity of adversarial and obfuscated malware exposes the traditional detection systems to severe challenges as malware authors employ techniques such as packing, encryption, irrelevant code insertion, and code metamorphism to disguise malicious intent and evade feature-based or signature-based detectors [2, 5] and adversarial attacks craft subtle perturbations in malware samples to mislead machine learning models without altering the malware’s functionality [6, 7]. These strategies expose the vulnerabilities of unimodal detection systems, which often fail to generalise beyond the specific feature space they were trained on.
These weaknesses are addressed by multimodal detection frameworks by combining diverse features and jointly learning representations that cross-validate and fuse evidence from multiple perspectives as approaches of integrating visual features with dynamic behaviours and graph-based static have demonstrated superior generalization against obfuscation and adversarial perturbations, capturing structural and semantic relationships that remain invariant under attacks [3, 8]. Adversarial resilient strategies which combine variational autoencoders (AEs) with MLP sharing feature extractors further revamp generalization to unseen malware [6] and these improvements point out to the limitations of unimodal or simply fused systems and highlight the importance of hybrid, multimodal frameworks for resilient malware detection.
Some existing multimodal approaches also struggle to effectively align diverse feature spaces and adaptively fuse cross-modal information under obfuscated and adversarial conditions [6, 9, 10] as single-modal detectors or simple fusion strategies also fail to capture the fine-grained semantic alignments and correlations necessary to maintain resilience when malware authors manipulate features or exploit modality-specific weaknesses.
Contrastive learning strengthens the model’s capacity to discriminate between malware patterns and adversarial perturbed variants by using the agreement between semantically related samples across modalities while minimizing false correlations [10, 11]. As well, adaptive cross-modal fusion mechanisms dynamically weight and integrate modality-specific and cross-modal features to improve resistance against obfuscation-induced distortions, noise, and inconsistencies as this fusion may allow multimodal malware detectors to maintain high detection accuracy while offering improved adaptability and generalization against evolving evasion strategies.
This study offers an improved multimodal malware detection system that fills these limitations by making the following contributions:
Fusing ResNet-50 for image features and MLP encoders for tabular information for strong multimodal representation that captures discriminative patterns.
Dynamically integrating features, adaptive fusion and contrastive cross-modal learning by aligning multiple modalities to improve detection against obfuscation and adversarial attacks.
This study enhances malware detection and offers a practical defense against adversarial and obfuscation perturbed threats by merging multimodal representation, robust cross-modal learning, and adaptive fusion.
2. Related Works
Malware detection has shifted towards multimodal detection systems to counter new-evasion techniques such as adversarial and obfuscation perturbation attacks that attempt to deceive individual unimodal systems. Different feature modalities such as tabular features, sequence representations, and image encodings are fused into one multimodal system to exploit invariant, fine-grained patterns, similarity intents and generalisation capabilities to maximise detection performance. Image-based detection usually employs deep convolutional neural networks (CNNs) to automatically learn useful structural, statistical, semantic and visual patterns in malware samples or extracted features (denoted as pixel encoded greyscale byteplot images).
For example, ResNet-50 achieved good performance on multiple malware variants [12]. Novel combinations of CNNs with vision transformers have broken through known performance barriers to achieve high generalisation behaviour on diverse malware variants [13, 14]. These models show that good visual feature encoding provides a resilient baseline for detection.
Tabular features that approximate from static features like system call sequences, metadata or dynamic features such as API call frequencies can be used with popular machine learning models with bagging or boosting techniques, such as Light Gradient Boosting machines (LGBM) with good performance records [15]. Multimodal contrastive learning setups show that training in a cross-modal fashion can improve the feature alignment to produce robust feature vectors even when the data is sparse or corrupted [16]. Sequence features like package names or permissions can be transformed with time sequence models trained with RNNs or CNN-GRU hybrids to learn obfuscated dynamic changes in the sequence, outperforming traditional n-gram models that simply learn fixed combinations of time sequence states for malware detection – thus supporting deployment in less powerful execution environments [17].
Multimodal pre-training with sequence level contrastive learning can reinforce the cross-modal relations and achieve more effective fusion of tabular, image and sequence modalities [18]. Obfuscation and adversarial perturbed attack are still long-standing challenges for malware detection. Recent researches on hybrid models such as mixed between MLP and VAE show their effectiveness to resist against unknown adversarial perturbations by disentangling the latent features [6], adaptive cross-modal fusion mechanisms achieve resiliency while flexibly weighting features of devices to cancel out any noise or disturbance from one modality [19, 20]. For extracting at the best of CNN-based image analysis, sequence learning, like tabular feature modelling, full integration or fusion of image, sequence and tabular data remain considerable unsolved issues [21, 22], simple concatenation has limited effectiveness in considering cross-domain features and correlations. Typical studies ignore performance evaluation in simulated obfuscated then adversarial environments. Our work that uses the ResNet-50 and MLP encoder along with contrastive learning and adaptive fusion to align the features from image, sequence and tabular modes while dynamic weighting of features brings more effectiveness [18] to minimize noise or disturbance in any modality even in adversarial environments than other methods.
3. Methods
3.1. Dataset Description
The Multimodal CIC-MalDroid2020 dataset, a publicly accessible benchmark for Android malware detection in clean, hostile, and obfuscated scenarios, is used in this study. An Android program (APK) is represented by each sample, which is classified as either benign or malicious. Only two of the three complimentary modalities offered by the dataset are utilized:
Bytecode from APKs is translated into RGB images using image modality in order to maintain the code’s spatial and structural patterns. These RGB images extracted from .DEX files are used to extract visual characteristics that are resistant to typical adversarial and obfuscation attack techniques. While the static features extracted from .APK files includes static components that provide ordered tabular data for each sample, such as permissions, API call, and metadata. These features capture intents and patterns of activity that are crucial for detecting malware. The dataset contains clean, obfuscated, and adversarial splits, each of which has both tabular and image modalities to give balanced representation for training, evaluation and testing.
3.2. Adversarial and Obfuscation Scenarios
Obfuscated samples, malware is transformed using common techniques such as packing, code reordering, junk code insertion, or encryption to alter surface representation but retain functionality. All subsets (clean, adversarial, and obfuscated) are mutually exclusive, and stratified sampling ensures consistent class distributions across training and testing sets which are all part of the secondary used. The details of the obfuscation and adversarial perturbations are not made available with the dataset source.
3.3. Data Pre-Processing
Image modality: All images are resized, augmented, and normalised during training using rotations, random crops, colour jitter, cutout masking and flips. For evaluation, images are resized and centre-cropped deterministically.
Tabular modality: Features are standardised through z-score normalisation to ensure consistent scaling:
where: x(t) = original tabular feature vector and μ, and σ = mean and standard deviation from training data respectively.
3.4. Problem Formulation
The detection task is formulated as supervised multimodal classification where each sample i is represented as:
xi = (xi(v), xi(t)),
where xi(v): image input of the ith sample (visual byteplot or greyscale) and xi(t): tabular feature vector of the ith sample. The objective is to predict a label yi ∈ {1,2,…, C}, where yi: true class label of sample i, and C: total number of malware and benign classes.
Image Encoder (fv) → ResNet-50 produces visual embeddings:
zi(v) = fv(xi(v)),
where zi(v): latent visual embedding from the image encoder and fv(⋅): ResNet-50 image encoder function.
Tabular encoder (ft) → MLP produces tabular embeddings:
zi(t) = ft(xi(t)),
where zi(t): latent embedding from tabular encoder, and ft(⋅): MLP tabular encoder function.
Cross-modal fusion (g) → Combines embeddings:
zi = g(zi(v), zi(t)),
where zi: joint representation after fusing visual and tabular embeddings and g(.): adaptive cross-modal fusion function.
Classifier (h) → outputs class probabilities:
Where
where T: temperature parameter, N: batch size, ziimg, zitab: normalised embeddings for sample i, and ⋅: dot product for similarity.
3.5. Model Architecture
The proposed framework integrates image and tabular modalities as shown by the detailed model architecture and flow diagram in Figure 1:
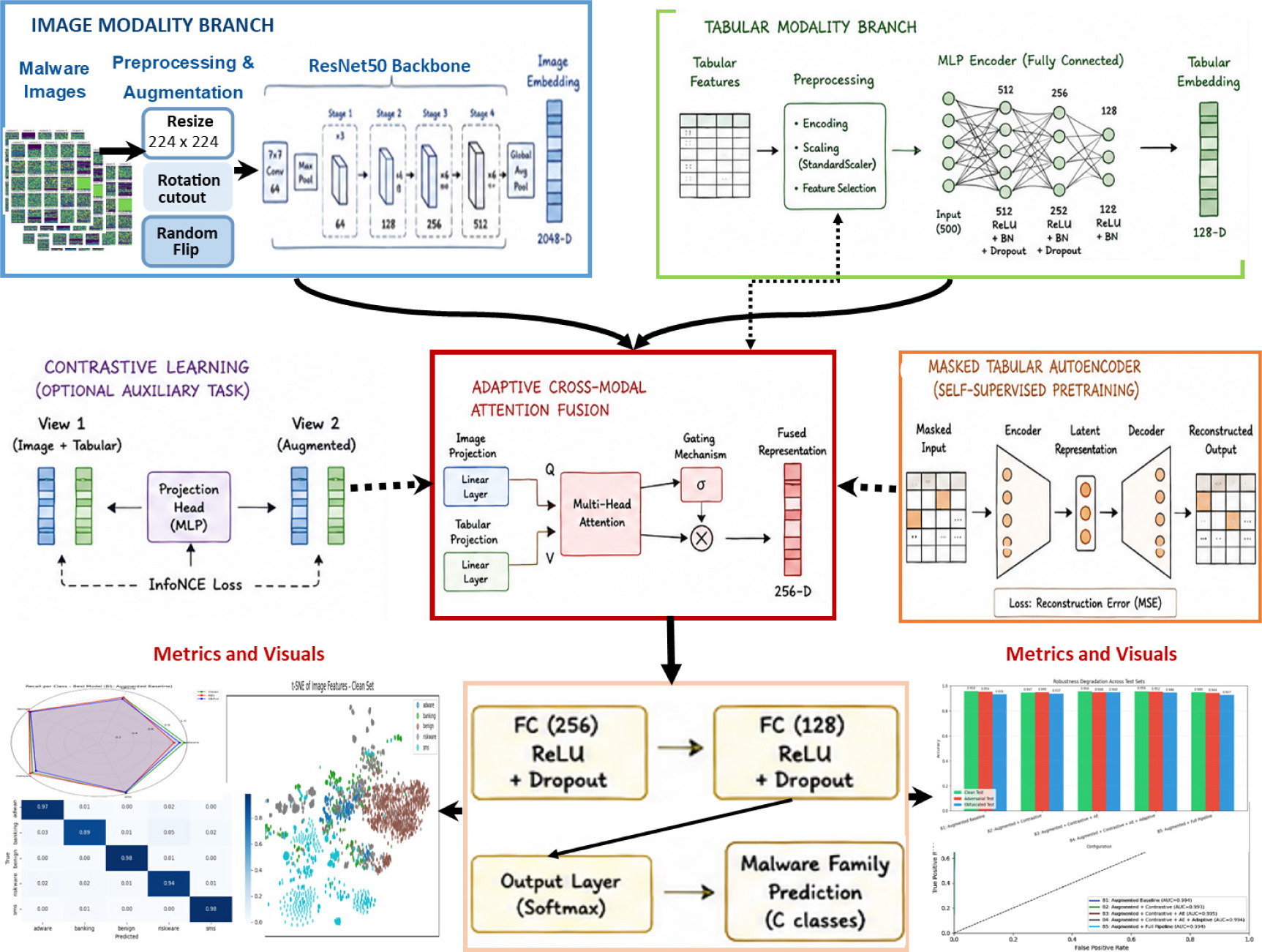
ResNet-50 extracts visual embeddings from byteplot or greyscale images.
An MLP with masked autoencoder pre-training captures tabular feature correlations.
Contrastive learning aligns modalities in a shared latent space.
Adaptive fusion weights each modality according to its relevance per sample.
The fused representation is passed to a fully connected classification head.
3.6. Training and Implementation
The multimodal malware detection framework was implemented using the PyTorch deep learning library in the Kaggle Notebook optimized by using the GPU. The model integrates two modalities which are malware image representations and tabular behavioural features extracted from dynamic analysis. Image-based features were extracted using a pre-trained ResNet-50 network, where the final classification layer was finetuned to obtain a 2048-dimensional feature vector. The tabular modality was processed using a MLP consisting of three fully connected layers of sizes 512, 256, and 128, each followed by batch normalisation, ReLU activation, and dropout regularisation. To improve feature learning, a masked tabular autoencoder was first trained to reconstruct partially hidden tabular features using mean squared error loss. The learned encoder weights were then used to initialise the tabular encoder. Additionally, contrastive learning was applied by generating two augmented views of each image features and optimising a contrastive loss with temperature τ = 0.1 to learn invariant representations and intents. During training, mix-up augmentation was used to combine and fuse samples from different classes. Model parameters were optimised using the AdamW optimiser with learning rates of 1×10–5 for the image encoder and 1×10–4 for other modules, with a cosine annealing learning rate scheduler. Training was performed with a batch size of 32 and early stopping with a patience of five epochs based on validation accuracy results.
3.7. Evaluation Metrics
Performance is measured using:
where C is the total number of classes. χ
where:
b = misclassified by model 1 but correct in model 2
c = correct in model 1 but misclassified by model 2
Reject null hypothesis if χ2 > 3.841 for α = 0.05
Metrics reported per-class and per-test configuration (clean, adversarial, and obfuscated).
4. Results
We evaluated five multimodal configurations (B1–B5) on clean, adversarial, and obfuscated test sets. The configurations progressively integrate contrastive pre-training, a tabular masked autoencoder, adaptive cross-modal attention, and tabular noise injection during fine-tuning. All models were trained on an augmented dataset comprising clean, adversarial, and obfuscated samples under a stratified train-test-val split. The distribution of samples across training, validation, and test sets is presented in Table 1.
Table 1
Dataset split after leakage-free stratification.
| Split | Clean | Adversarial | Obfuscated | Total |
|---|---|---|---|---|
| Training (augmented) | 10,521 | 3872 | 3629 | 18,022 |
| Validation (normal) | 1169 | - | - | 1169 |
| Test (normal) | 5008 | - | - | 5008 |
| Test (adversarial) | - | 968 | - | 968 |
| Test (obfuscated) | - | - | 910 | 910 |
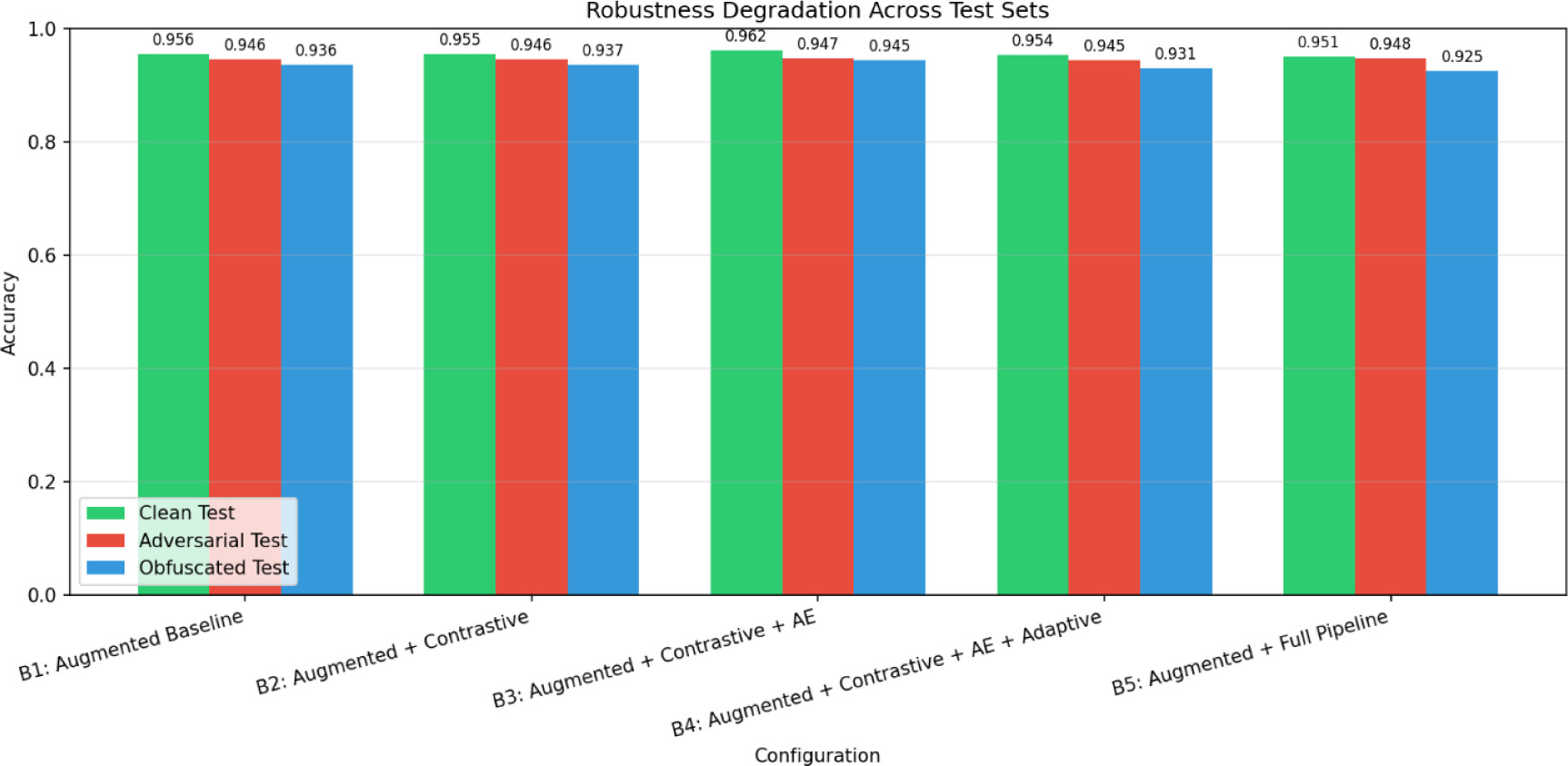
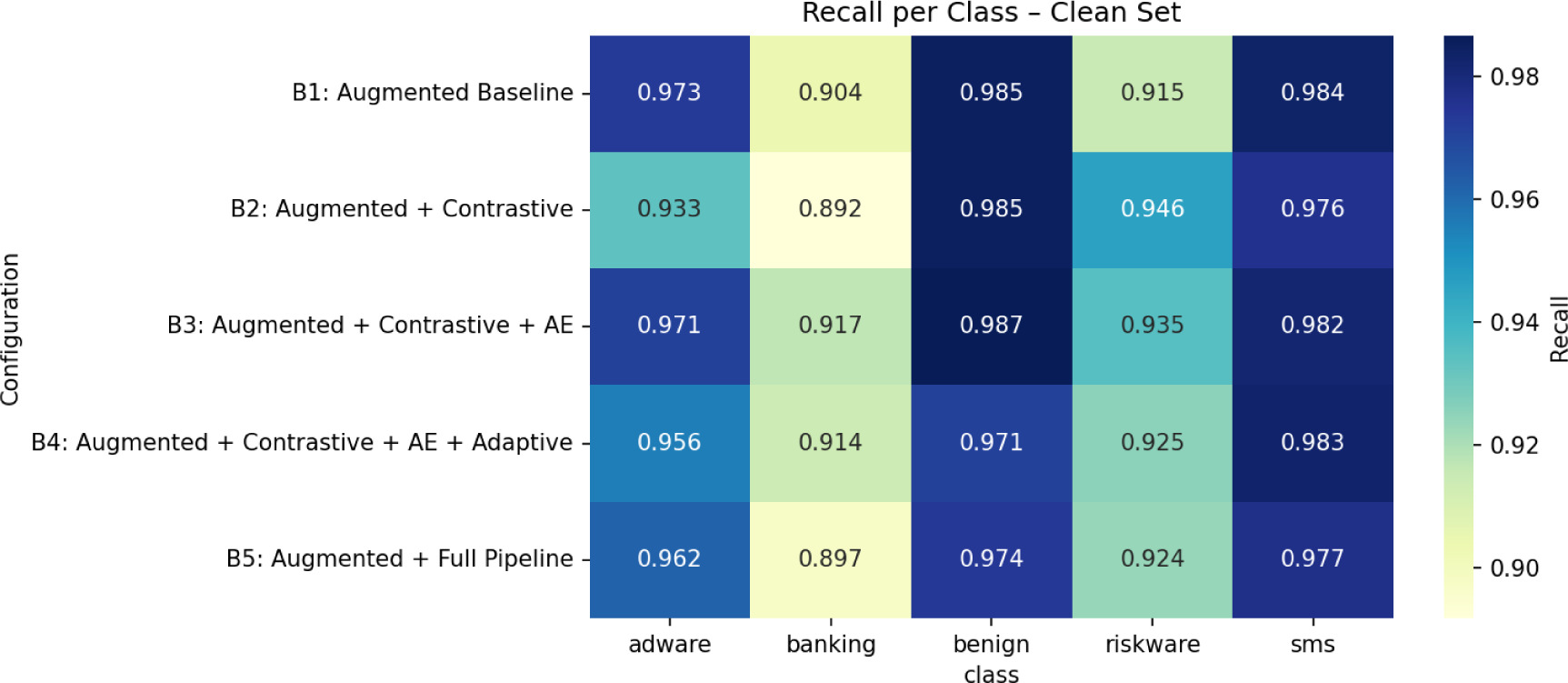
The augmented baseline (B1) has already demonstrated strong resilience, achieving 95.6% of accuracy on normal malware sample while maintaining a high performance on obfuscated samples of (93.6%) and adversarial samples of (94.6%). These findings suggest that incorporating the adversarial perturbed and obfuscated data during training offers a strong basis for distributional generalization and manipulation resistance. When the classification model is previously trained on a variety of augmented data, adding contrastive pre-training (B2) results in about comparable performance across all test sets, indicating that the contrastive objective does not offer a significant additional benefit.
The addition of the tabular masked autoencoder (B3) results in a significant improvement. The accuracy of detecting regular malware samples (clean) climbs to 96.2%, which is the greatest of all configurations; on obfuscated samples, the accuracy also rises to 94.5%, an absolute gain of over one percentage point over B2. However, when adaptive cross-modal attention (B4) is used instead of simple concatenation, the accuracy of obfuscated samples falls to 93.1%. Every test set exhibits the same decline. This decrease suggests that the acquired gating mechanism may lead to instability in the event of a distribution shift. The whole pipeline (B5), which incorporates tabular noise injection during fine-tuning, achieves the best detection accuracy of 94.8% on adversarial samples and 92.5% on obfuscated samples. This suggests a resilience trade-off between systemic corruption and targeted perturbations, and the complete accuracy comparison is shown in Table 2.
Table 2
Accuracy comparison across configurations.
The resilience degradation across clean, adversarial, and obfuscated test sets is visualised in Figure 2, which highlights that B3 exhibits the smallest performance drop under perturbation and manipulation, whereas B5 shows the largest degradation on obfuscated samples.
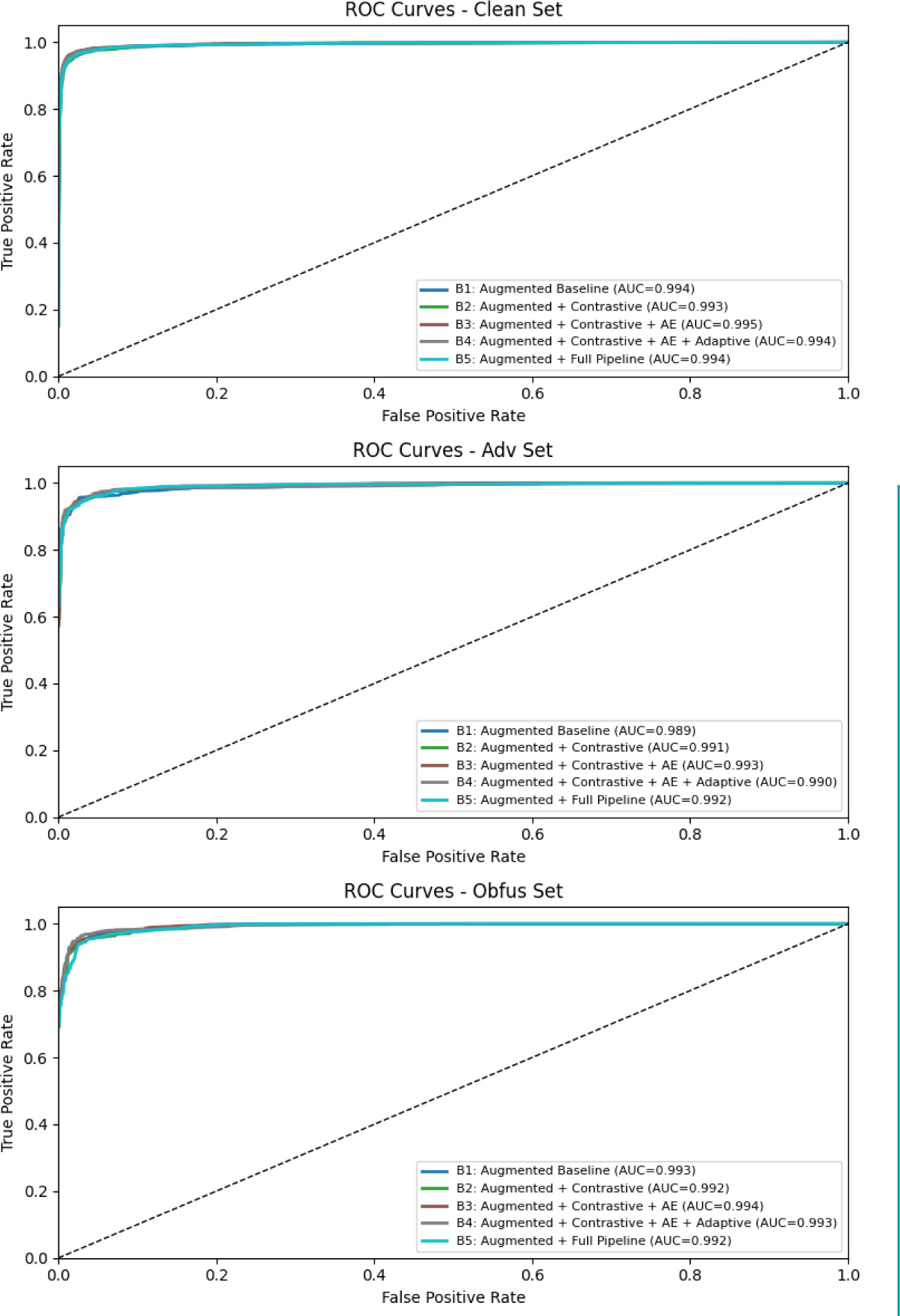
To assess whether the observed performance differences are statistically meaningful, McNemar’s tests were conducted between consecutive configurations. No significant differences were observed between B1 and B2 (p > 0.86) which confirms that contrastive pre-training alone does not meaningfully alter predictions. The improvement from B2 to B3 is statistically significant on the clean test set (p = 0.0042), reinforcing the contribution of the masked autoencoder to improved representation learning. However, the addition of adaptive attention (B3 vs. B4) results in significant performance drops on both normal malware (clean) samples (p = 0.0012) and obfuscated data (p = 0.0485), as this confirms that this fusion strategy is detrimental in the present setting. It is clear that tabular noise injection does not result in a significant improvement because the differences between B4 and B5 are not statistically significant (p > 0.18). Using macro-average receiver operating characteristic (ROC) curves, the models’ discriminative ability is further investigated. According to Figure 3, B5 slightly outperforms B3 on adversarial samples (0.992), but B3 obtains the best area under the curve (AUC) on typical malware (clean) samples (0.997) and obfuscated samples (0.993).
The distribution of resilience gains among malware categories is not consistent, according to a more thorough per-class analysis. On the basic malware (clean) test set, every setup consistently performs well in the Benign, Adware, Riskware, Banking, and SMS classes. With a clear high recall for benign and SMS samples, B3 offers the most balanced F1 performance across categories. Table 3 shows each configuration’s per-class F1 scores.
Table 3
Per-class F1 scores across configurations and test sets.
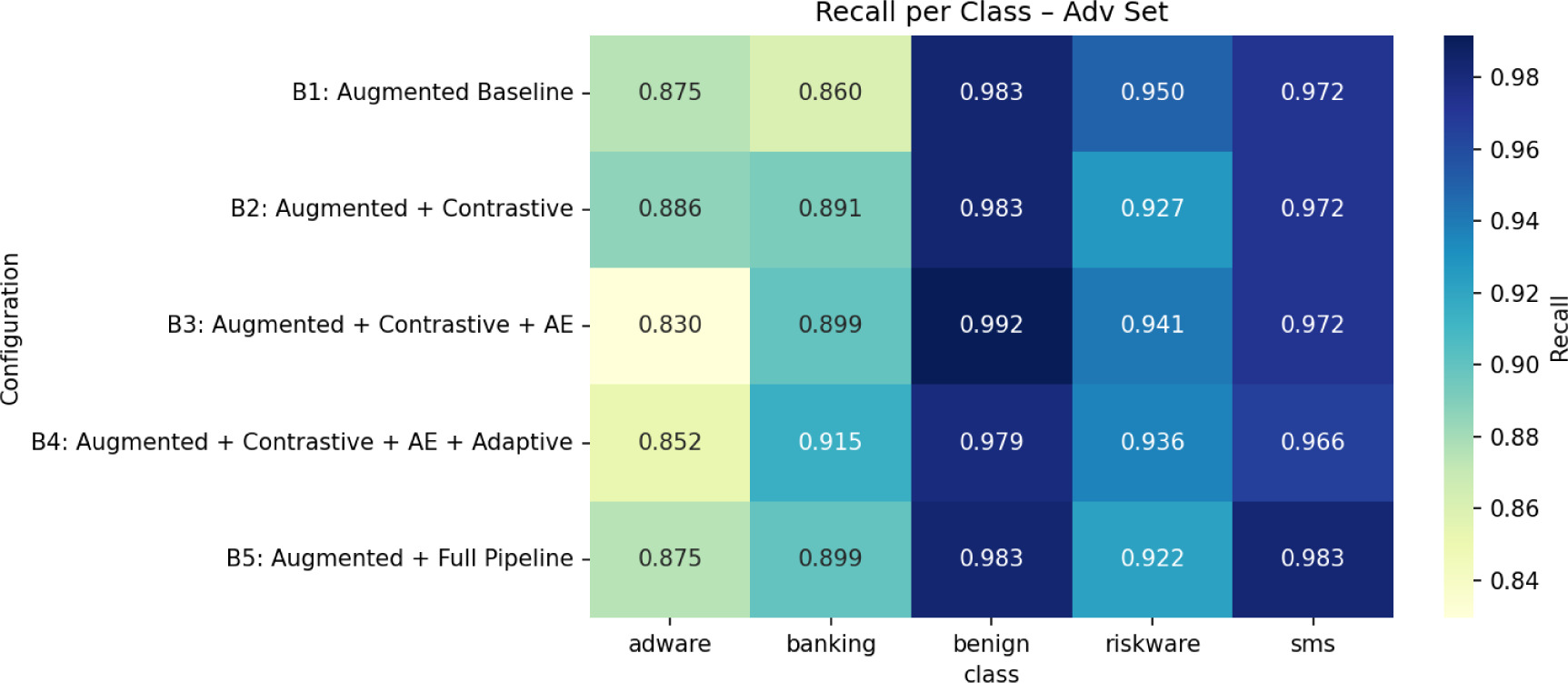
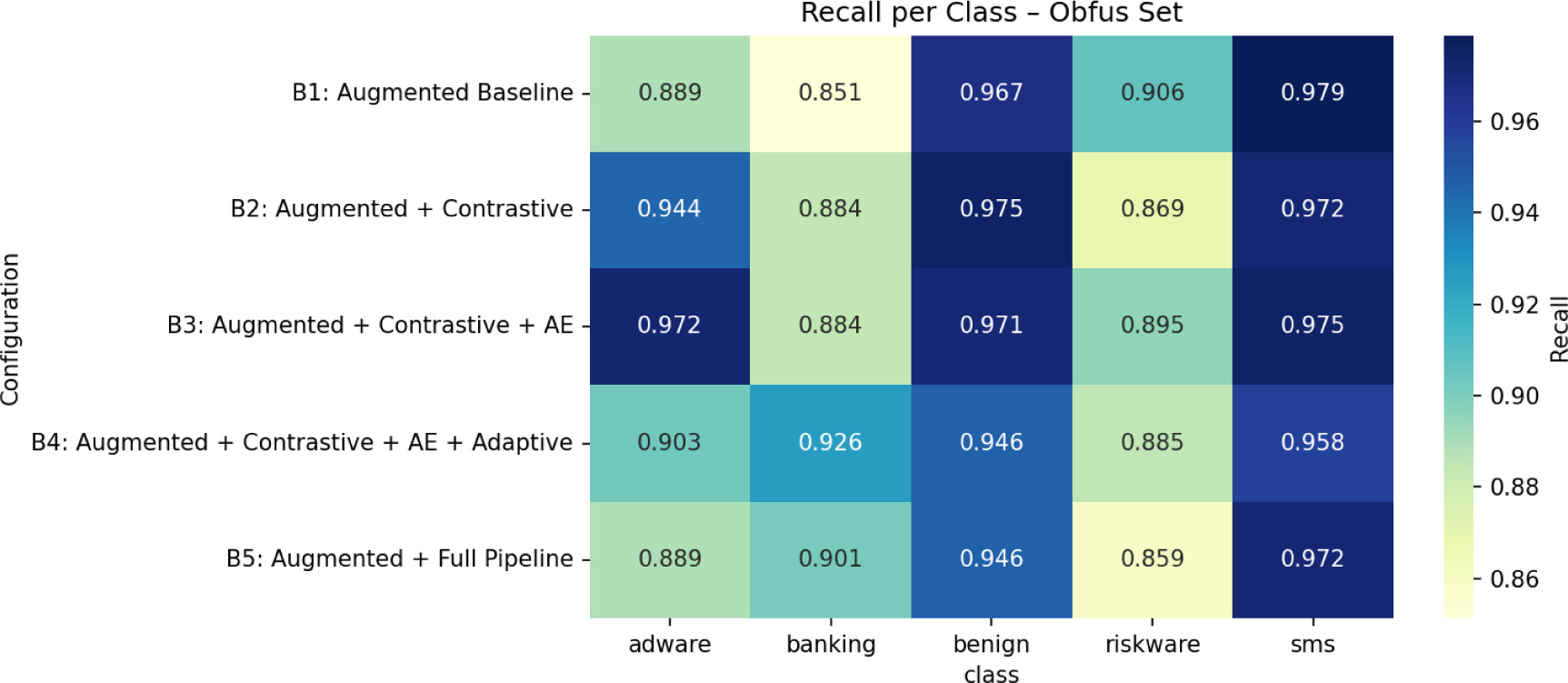
Riskware and banking are the most difficult classifications under adversarial settings, and B5 achieves the highest recall for these categories, which explains its slight overall adversarial sample advantage. On the other hand, adware turns into the most vulnerable class on the obfuscation sample. B3’s improved obfuscated detection accuracy is explained by a significant improvement in adware recall when compared to other settings. The best adversarial model (B5) recall patterns across test sets are shown in the radar visualization in Figure 4, which highlights the model’s advantages and disadvantages across classes.
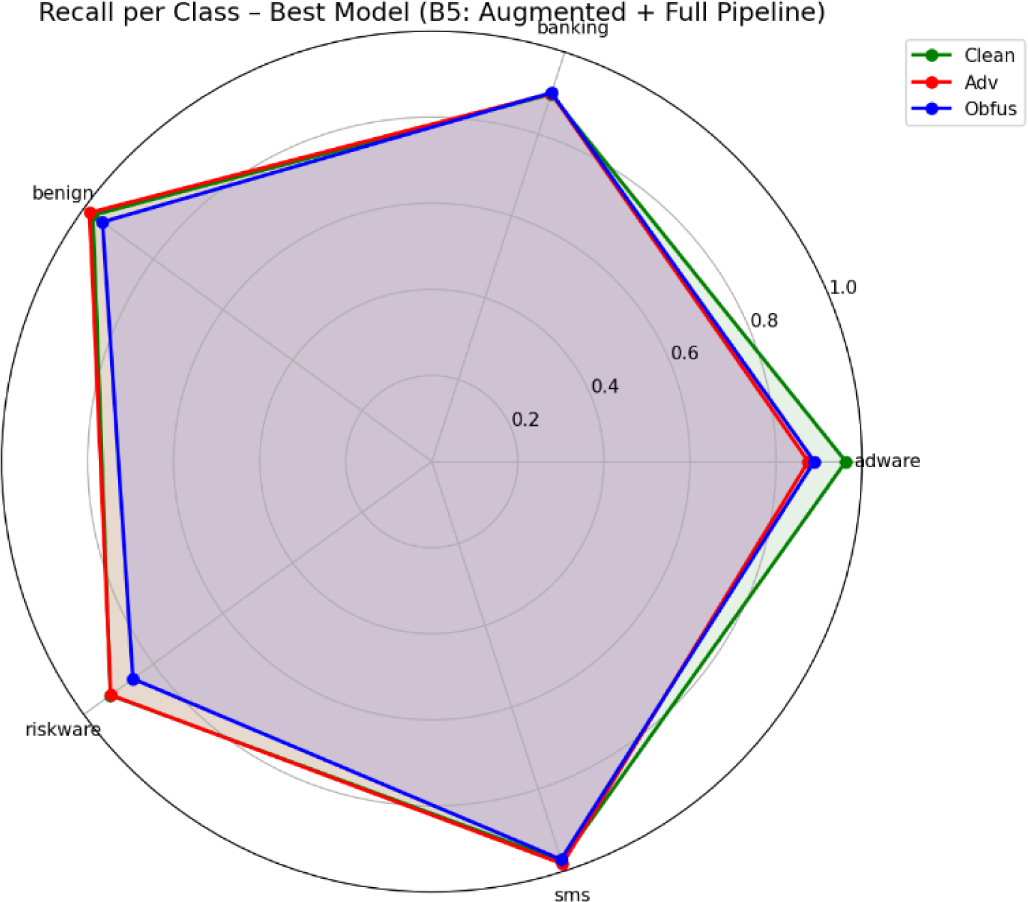
Image features extracted by B5 were subjected to t-SNE in order to gain a better understanding of feature space behavior and intents. Normal malware (clean) samples form well-separated clusters that correspond to the five classes, as illustrated in Figure 5. On the other hand, adversarial and obfuscated samples show more overlap, especially across riskware and adware, which is consistent with the recall decreases found in the per-class analysis.
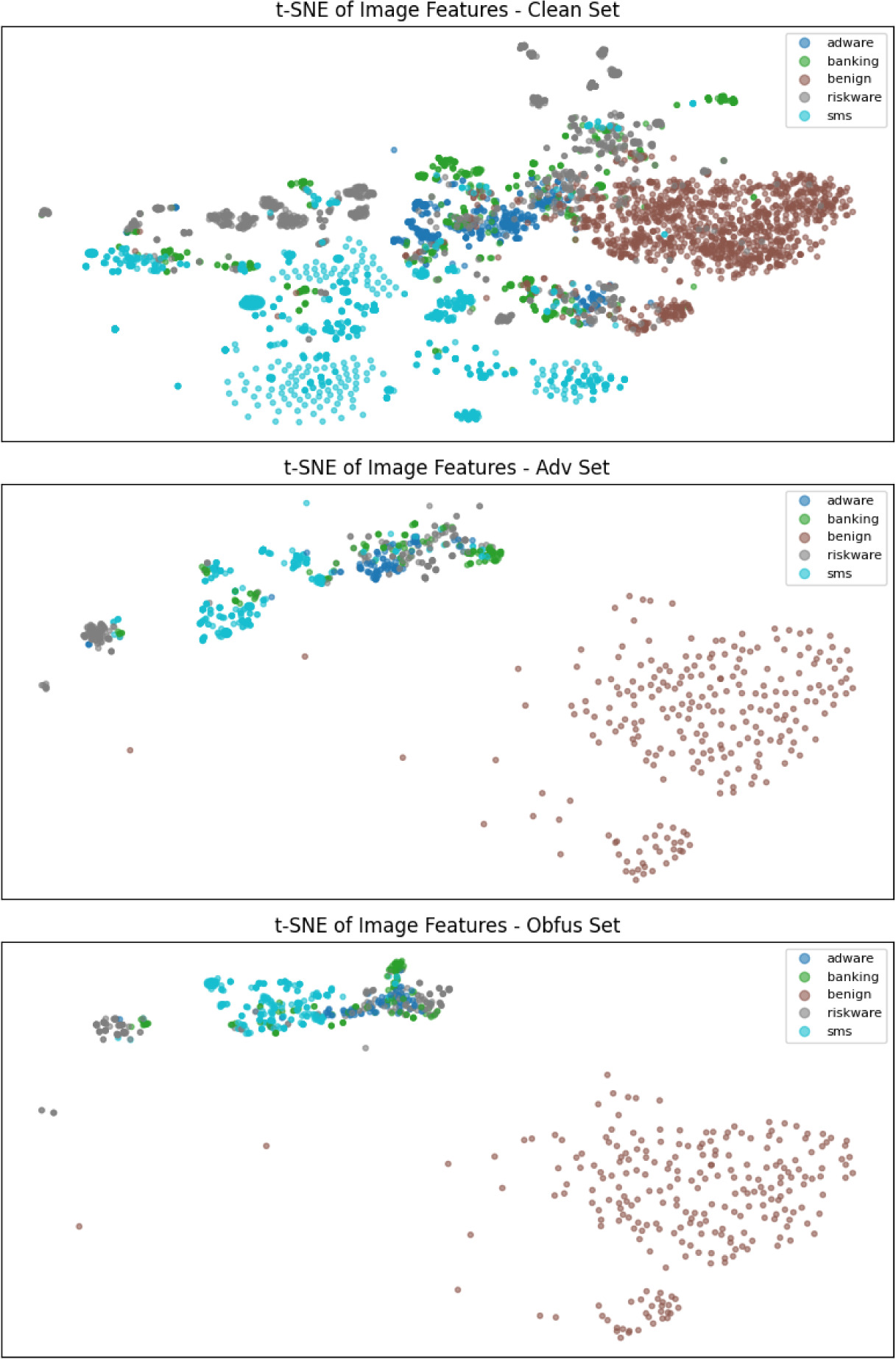
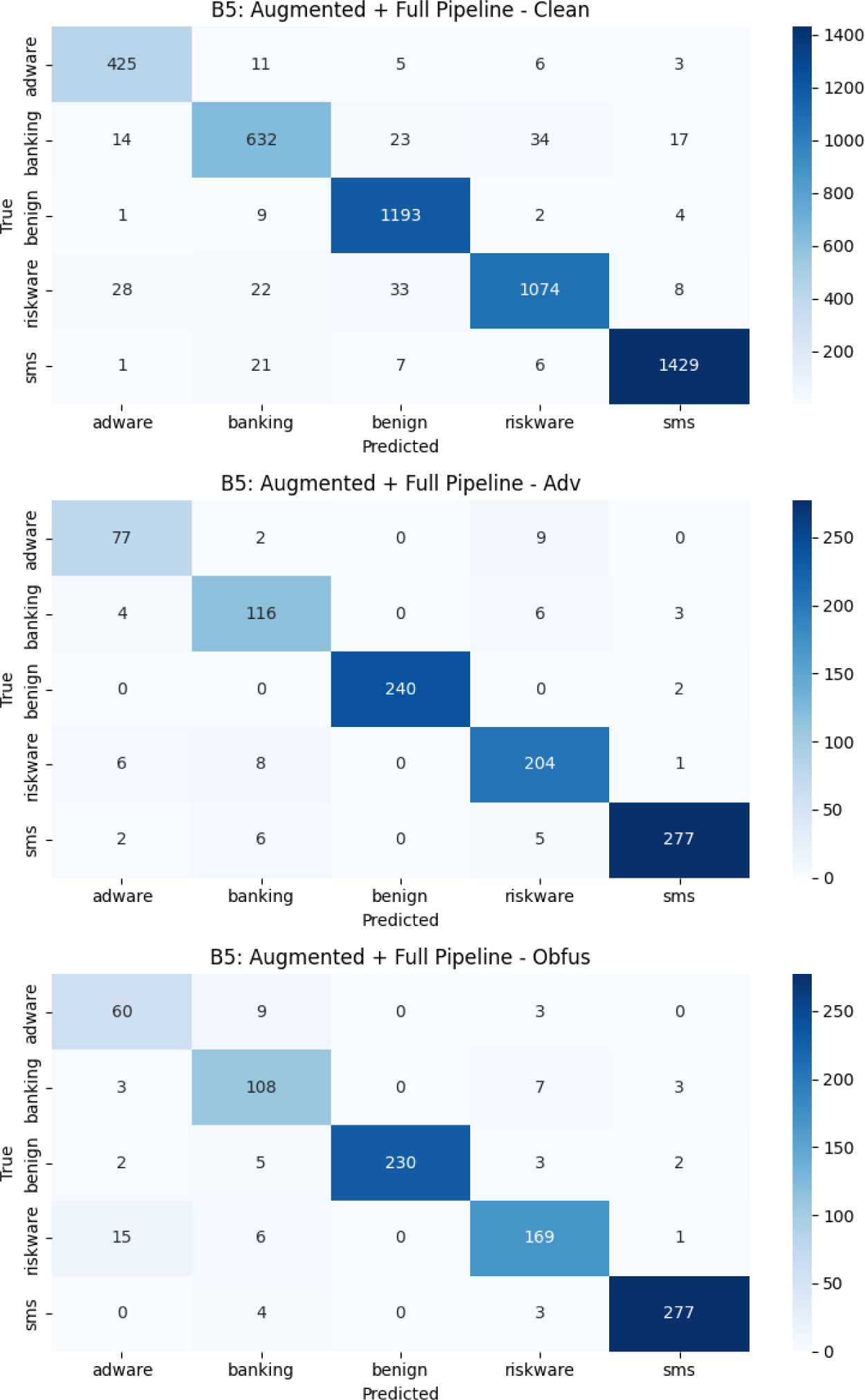
Figure 6 displays normalized confusion matrices for B5. Misclassifications are rare and mostly limited to semantically comparable classes on typical malware (clean) data. Confusion develops under adversarial and obfuscated situations, especially when riskware and adware are involved, demonstrating the susceptibility of certain classes to disruptions.
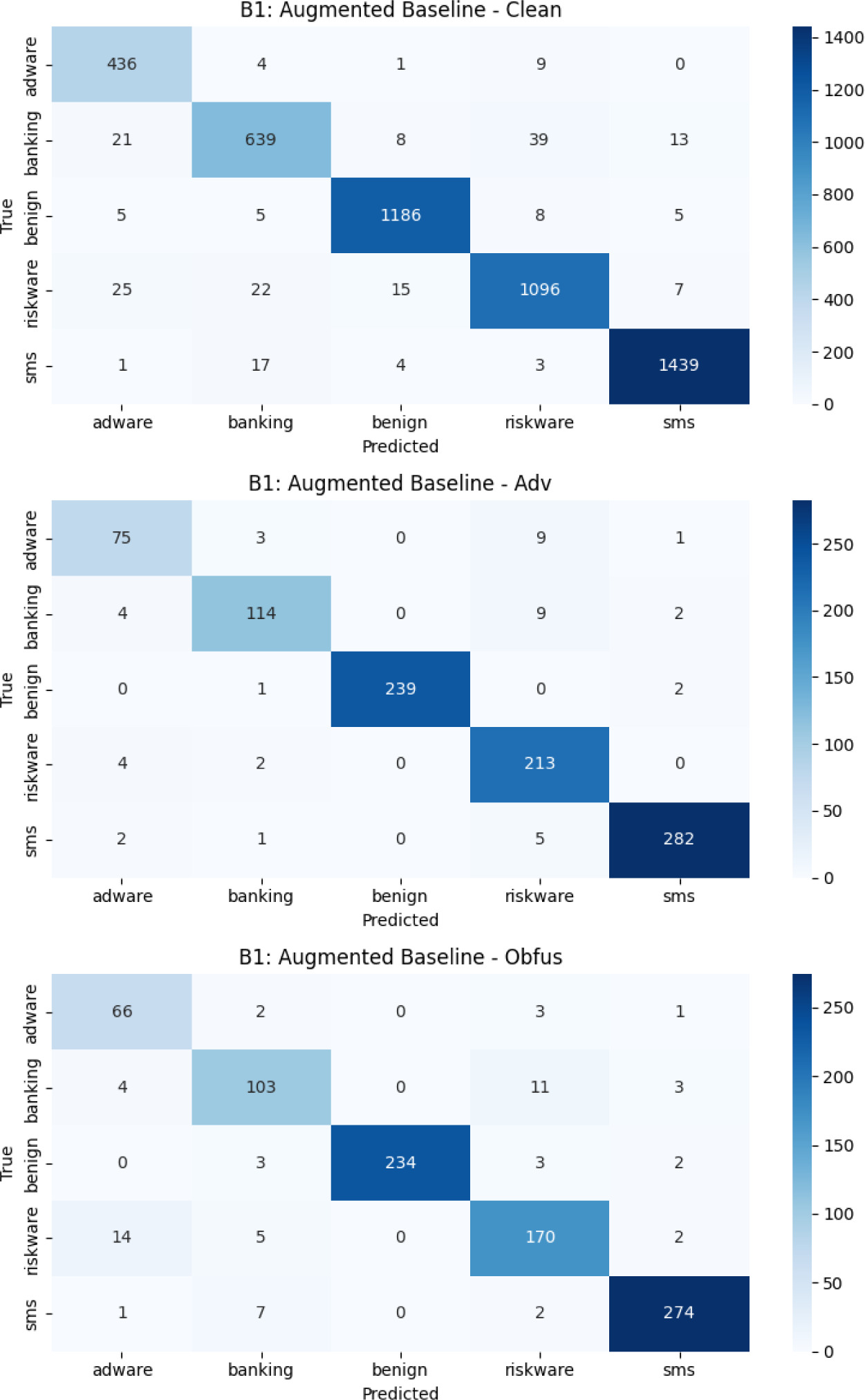
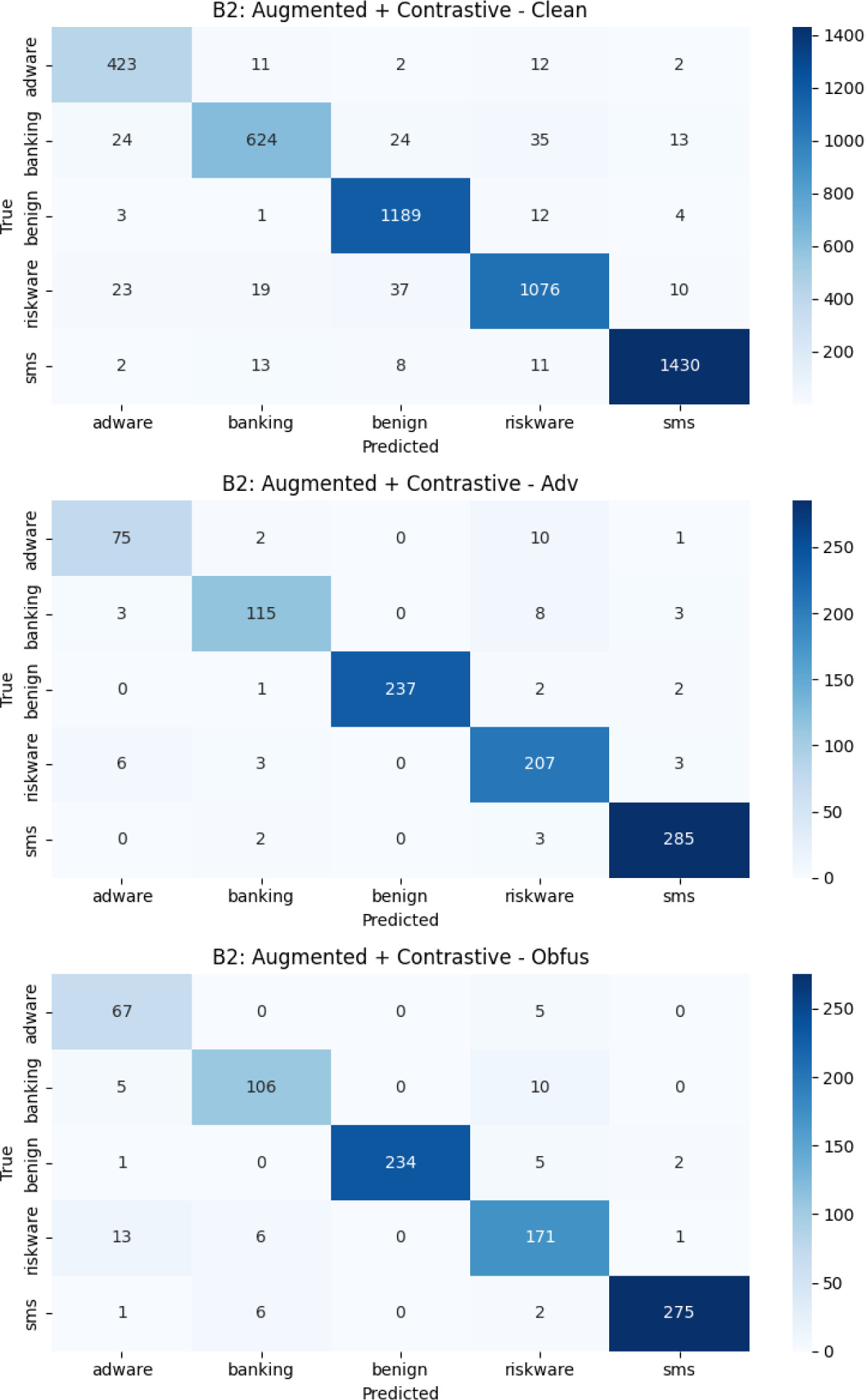
Figures 7–10 give confusion matrices for each configuration (B1–B5) across all test sets for completeness, showing how misclassification patterns or intents changed when new components were added.
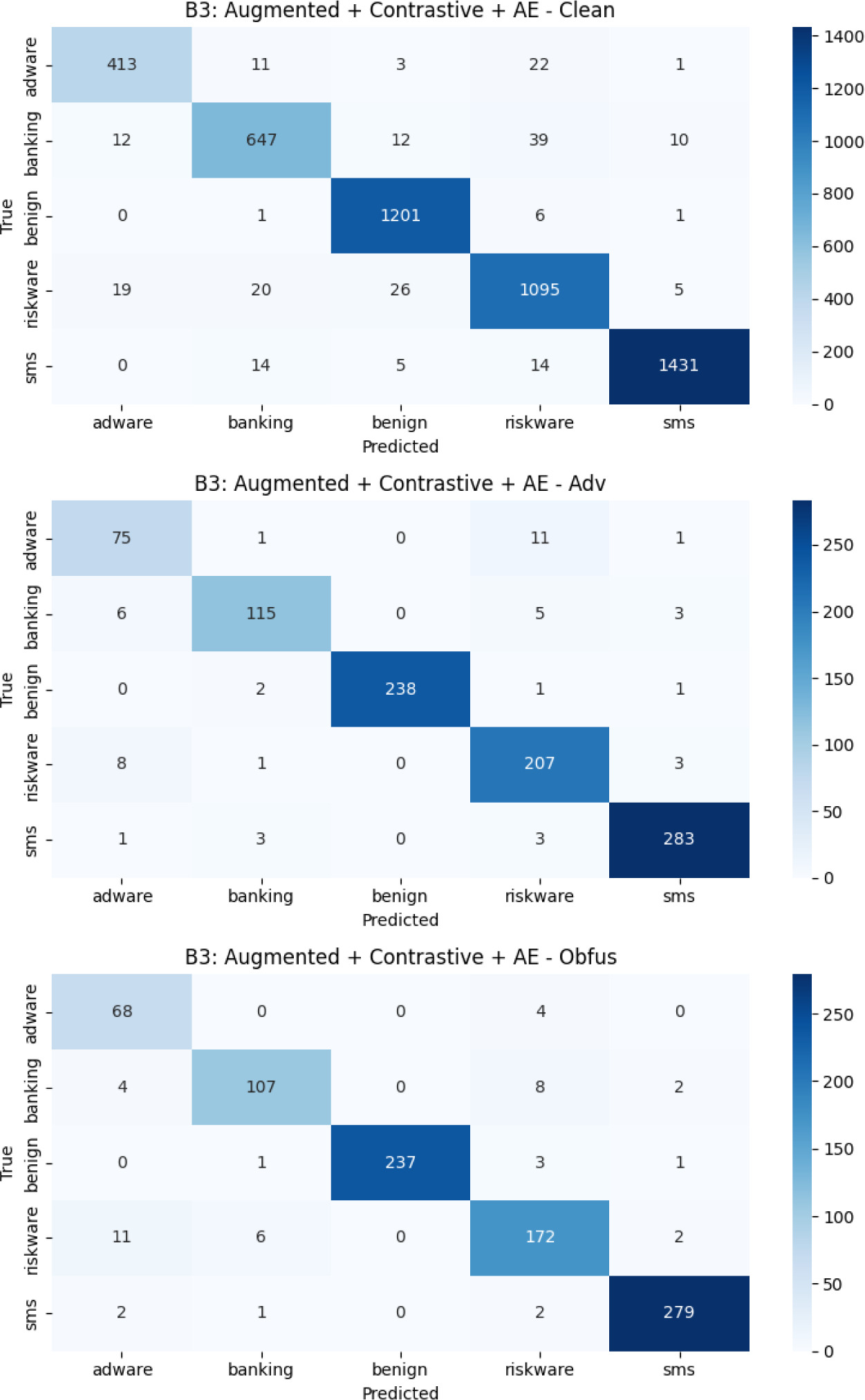
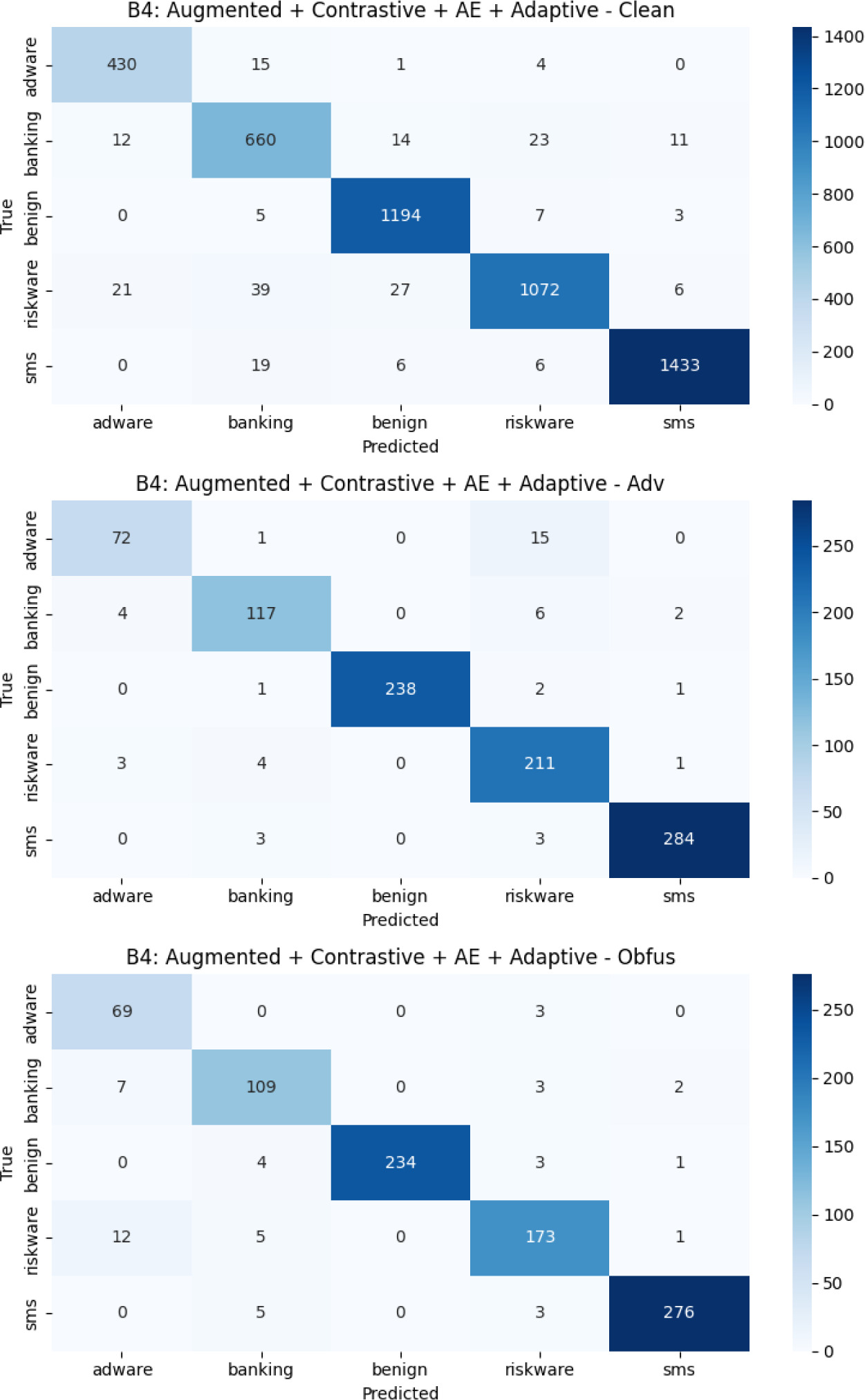
Ablation research (B1–B5) was carried out to separate the contribution of each architectural element. Contrastive pre-training by itself produces very little change in the presence of more training data, indicating its modest added advantage. The masked autoencoder, which significantly improves obfuscation resilience and clean performance, is the most beneficial and important component. Conversely, adaptive attention results in statistically significant degradation, most likely due to unstable modality weighting during distribution shift while by increasing hidden manipulations and providing a minor adversarial advantage, tabular noise injection supports the observed resilience performance. Recall per class-wise behavior across configurations are shown in Figures 11–13.
These results establish that B3 (augmented baseline + contrastive + masked autoencoder) is the most resilient and balanced configuration, whereas B5 offers a minor advantage against adversarial perturbations at the expense of the obfuscation sample’s resistance. These findings prove that resilience is not a monolith as architectural choices that strengthen resilient to one type of perturbation may concurrently weaken resistance to another.
5. Conclusions
This study investigated the longevity of a multimodal Android malware detection system in normal, adversarial, and obfuscated environments. A comprehensive study of five configurations revealed that resilience is more dependent on representation quality than architectural complexity. Training with enhanced data established a solid foundation for all test distributions. However, tabular masked autoencoder pre-training showed the greatest improvement in clean and obfuscated sample detection performance. In contrast, adaptive cross-modal attention decreased performance during distribution shift, demonstrating that greater fusion complexity does not always improve resilience. Tabular noise injection provided a modest advantage against adversarial perturbations while decreasing susceptibility to obfuscation samples, indicating a trade-off between modification types.
This combination of enhanced training and masked autoencoder pre-training resulted in the most balanced and consistent performance. These findings highlight the importance of rigorous module selection and assessment across multiple threat scenarios for resilient multimodal malware detection, rather than relying solely on clean sample detection accuracy. To improve detection performance and robustness even further, future research should look into supervised contrastive aims, more reliable cross-modal fusion processes, and adaptive noise scheduling techniques. Long-term generalization under adversarial drift can be better understood by comparing different datasets and malware streams.

