
1. Introduction
Where previous-generation influence campaigns relied on large teams, manual scripting, static messaging, or basic semi-automated bots, artificial intelligence (AI) – specifically large language models (LLMs) – enables high-speed, adaptive content generation at scale with minimal human intervention. Such systems can produce persuasive content in multiple forms and lengths [1] at low cost and with considerable rhetorical flexibility. The potential of LLMs to generate misinformation, disinformation, or propaganda is a theme of interest in risk assessments [2]. Perhaps as a response and a reflection of the importance of such capabilities, the World Economic Forum’s 2025 Global Risks Report identifies misinformation and disinformation as the top global risk [3]. Additionally, North Atlantic Treaty Organization (NATO) has flagged AI-enabled disinformation and information operations as issues of concern [4].
With AI, strong propaganda capabilities move within reach of non-state actors, including small organisations, micro-actors, and even individuals using commodity hardware and software. This expands concrete abilities to shape political discourse, manipulate public opinion, undermine trust, sustain discontent, or fuel conflicts, including armed conflicts. In this sense, AI can act as a force multiplier for information operations and, potentially, for longer-duration cognitive-warfare activities [5], or related risks to social fabric cohesion [6].
Although fabricated falsehoods can spread more rapidly than factual information [7], they still require deliberate generation or transformation into usable narratives. Until recently, operational AI use for these purposes was limited [8] and centred on LLMs accessed via controlled application programming interfaces (APIs), where providers can detect and block misuse [9]. While LLMs can produce human-authentic, politically aligned content [10], to date no confirmed state actor has been observed conducting a
significant operation using server-side LLMs. A reasonable explanation follows from tradecraft: covert information operations cannot reliably rely on third-party infrastructure [11] without incurring discovery or a disruption risk, including potential exposure of aims and targets. Reports describe actors deploying AI-driven networks for targeted influence, with indications of adaptability across regions and contexts [12], but these typically involve contracting specialised services, rather than reliance on general LLM providers. Concurrently, major platforms are piloting LLM-based engagement agents – for example, Meta’s planned ‘bot personas’ on Facebook and Instagram – highlighting both the commercial pull for agentic systems and the related risks [13, 14].
By contrast, the situation changes fundamentally with small language models (SLMs). Offered as open-weight models, SLMs can be downloaded, deployed locally, fine-tuned, or used without oversight, and operated covertly – unlike API-dependent LLMs operating in the cloud. This makes SLMs well suited to covert deployment by actors who prioritise deniability and persistence over potential superiority in LLM performance.
Building on this shift, this paper examines the practical use of SLMs in manual, semi-automated, and potentially automated influence operations – an ‘AI propaganda factory’. Our focus is the feasibility of building an AI propaganda pipeline capable of sustained, consistent, and stable content generation. To this end, we evaluate political, ideological, and psychological traits when engaging with real-world discussion content from online boards. To demonstrate capability for smaller-scale actors, all tests are performed on commodity hardware, measuring how SLMs facilitate the operation of personas [15] configured to simulate human-like aspects, such as demographic descriptors, rhetorical tone, and political stance. The core performance metric – persona fidelity (PF) – assesses how consistently these traits are expressed across generated outputs. We avoid the use of human evaluators or annotators and rely solely on an SLM-as-judge approach. Taken together, this design supports the conclusion that fully automated influence-content manufacturing is within reach and constitutes a contemporary, rather a future risk; our measurements also indicate potential detection techniques that can inform defences against AI-generated influence content.
Indications for defence. Our findings reveal a duality: while AI personas maintain remarkably stable expression across contexts (enabling sustained influence operations), this very consistency may also enable detection. Defenders should consider behavioural consistency analysis, as excessive stability across diverse contexts may indicate automation.
2. Paper Organisation
This paper is organised as follows. Section 2 (Research Questions) surveys prior work on disinformation and persuasion, persona designs and metrics, and LLMs as evaluators, and clarifies our scope. Section 3 (Methodology) describes the datasets in use, the design of experiments, evaluations, and measurements. Section 4 presents findings on how consistently personas are maintained and ideologies expressed in generated content. Section 5 develops system-level implications for operational feasibility, the broadened threat surface, and defence. Section 6 concludes this work.
3. Research Questions
We investigate the following questions.
RQ1 (Feasibility on commodity hardware). Can locally run language models achieve high PF and ideological adherence (IAS) across diverse political personas?
RQ2 (Context sensitivity). How does added conversational context change PF and IAS?
RQ3 (Model vs. persona effects). How large are between-model differences relative to persona and engagement mode effects?
RQ4 (Extremity under engagement). Does engagement increase the rate of strong ideological content?
RQ5 (Automation readiness). Have we reached the point where influence operations can be fully automated – from content generation through quality assessment – without human oversight?
Observed effects: (i) persona-over-model–persona design matters more than model identity; (ii) engagement as a stressor–counter-argument prompts strengthens IAS and increases extreme content.
3.1. Related works
Large language models have been studied for their capacity to generate content and simulate personas, but relatively few works probe persona control in debate-style settings or examine deployment with small, locally run models under fully automated evaluation.
3.1.1 Disinformation, persuasion, and detection
Williams et al. [10] tested 13 LLMs on election-disinformation tasks and reported that human evaluators could distinguish AI from human content only 42% of the time; the study centres on human-judged persuasiveness and safety compliance rather than persona consistency or a threaded debate context. An unattributed field report [16] on Reddit ChangeMyView (CMV) posts indicates that AI-generated comments can outperform humans in persuasion, especially when personalised. Separately, Schroeder et al. [17] theorise malicious AI swarms, AI agent acting in coordination and optimising engagement, presenting a conceptual risk model that motivates empirical scrutiny but does not present an architecture or measurements. Matz et al. [18] run controlled user studies showing that tailoring messages to psychological traits increases persuasive impact. On the platform side, Radivojević et al. [19] deploy 10 political personas across GPT-4, LLaMA-2-Chat, and Claude-2 inside a (simulated) Mastodon social network environment and analyse detection via human perception. Industry evaluations have likewise used CMV with human raters to score model persuasiveness against human baselines [20]. Collectively, these works establish that language models can be persuasive. We do not focus on persuasion, but rather on metrics, and fully automatic evaluations for systemic conclusions.
Hackenburg et al. [21] show that sub-frontier models with applied post-training (reward-model selection) can render small, open-weight models (SLMs) highly persuasive: a tuned Llama-8B matched or exceeded GPT-4o in several settings, with information-dense conversation as the key lever and a persuasion–accuracy trade-off.
3.1.2. Value alignment and cultural traits
Kovač et al. [22] introduce ‘value stability’, using the Portrait Values Questionnaire (PVQ-40) – a standard 40-item instrument measuring 10 basic human values – to test how consistently models express values across synthetic short conversations. They report that most LLMs exhibit sub-human stability, particularly when applied to diverse fictional and real personas. Kharchenko et al. [23] assess whether responses reflect national cultural poles across 36 countries (Hofstede dimensions), finding that models can separate value poles but that alignment with a persona’s country or language is inconsistent. Both studies probe the consistency of stable traits (values or cultural poles), but do not focus on whether a model can sustain an ideological persona in adversarial debate settings.
3.1.3. Persona benchmarks and metric design
Samuel et al.’s PersonaGym [24] evaluates 200 narratively rich personas over several decision-theoretic tasks (persona consistency, linguistic habits, and expected actions), often using detailed biographical/lifestyle specifications. By contrast, we use concise operational persona descriptions (political orientation, rhetorical tone, and psychological style) mechanically to target ideological fidelity under debate context. Miyazaki et al. [25] propose reference-free, graded assessment of persona characteristics in conversation, rather than comparing to a fixed ‘gold’ text, judges rate how likely a given utterance would be produced by a target persona, aggregating multiple ratings (five crowd workers per item in their setup). This motivates our choice of graded, reference-free (i.e. without a gold answer) PF scoring; we operationalise it with a local LLM judge tailored to debate prompts.
3.1.4. llms as ideology measurers
O’Hagan and Schein [26] treat LLMs as measurement instruments: given text associated with elected officials, the model places each official on a left–right scale. The resulting scores align with standard benchmarks (e.g. roll-call and finance-based ideal points), and the authors interpret these judgements as capturing a public ‘zeitgeist.’ Their results illustrate that LLMs can provide valid numeric ideological judgements. Our focus is on distinct settings – persona-conditioned replies – while employing an automatic evaluator.
3.1.5. Scope and contribution
Relative to these lines of work, our study differs along three axes: (i) automated evaluation with a locally run, open-weight judge model (no human raters); (ii) debate-style prompts with minimalist, operational persona descriptions; and (iii) an end-to-end pipeline designed for feasibility on commodity hardware and independent of closed hosted APIs. Rather than measuring persuasion outcomes, we focus on PF, IAS, stylistic consistency, and context adaptation – core building blocks for a fully automated influence architecture. The motivation is to study the feasibility of such a system under operational conditions that actual attackers or defenders may encounter with societal implications.
4. Methodology
We apply small language models to evaluate the capacity to sustain configured persona characteristics across generated outputs in order to assess their operational potential and risks. Eight personas were operationalised as structured descriptions specifying ideological stance, rhetorical tone, and stylistic markers. Each persona was applied to prompts drawn from a corpus of 180 discussion threads from the r/ChangeMyView Reddit discussion board, where an original poster (OP) publishes a statement or question and other users offer replies. In each thread, the OP may select one comment as the winning reply that best addresses or changes their view. Using these prompts, models generated responses under controlled conditions; the resulting outputs were then evaluated on multiple dimensions of persona conformity and IAS.
4.1. Topics
We use CMV dataset from the Convokit project, retaining threads that meet two criteria: (1) the OP body length is between 50 and 600 characters; and (2) the thread contains at least one comment marked as the winning reply by the OP.
These bounds exclude too short or too long posts while preserving substantive but manageable discussion prompts (the setting was chosen to model circumstances of social media activity, where text content is bounded). From the filtered set, we extract threads in the order provided by the dataset, providing a fixed evaluation pool.
4.2. Personas
We instantiated eight personas (Table 1) from a fixed template with four behavioural fields: (i) ideology (far left, left, moderate, right, and far right); (ii) communication style (empathetic, aggressive, concise, and formal); (iii) tone (motivational, sarcastic, condescending, and analytical); and (iv) stance instruction (agree, disagree, neutral, sceptical, curious). Two demographic attributes, age and gender, were also specified as part of the persona block shown to the model. Each persona identifier is formed by concatenating ideology, style, and tone (e.g. moderate_empathetic_motivational). The instruction text listed these traits in plain bullet-point form, included only minimal demographic hints, and imposed operational constraints (e.g. no meta-AI disclosures, no personal names or affiliations, English-only output). To stress-test control, we balanced polarity and extremity and introduced deliberately incongruent tone–stance pairings. A soft target of 300 characters per reply was used. The same persona instruction texts (apart from field values) were reused verbatim across all prompts and models to ensure consistent conditioning. Minimal demographic hints (age and gender) were included as part of the persona template (although they played no role in the analysis). We selected eight personas to systematically vary ideology, communication style, and tone: moderate personas establish baseline anchors, ideological extremes (two far-left, two far-right) capture peak automation risk, and varied communication styles and tones test whether ideological control holds across different rhetorical approaches. We selected eight personas to systematically vary ideology, communication style, and tone: moderate personas establish baseline anchors, ideological extremes (two far-left, two far-right) capture peak automation risk, and varied communication styles and tones test whether ideological control holds across different rhetorical approaches. When reporting results, we omit age/gender, as these attributes were not evaluated, and listing them would be a risk, implying demographic effects we do not test.
Table 1
Eight persona configurations spanning ideology, communication style, tone, and stance.
Our methodology employs persona prompt design to steer model behaviour via structured attributes in the prompt. We deliberately restrict the persona block to a compact set of task-relevant communication dimensions (ideology, communication style, tone, and stance) instead of rich biographical profiles. Research work on principled persona prompting indicates that adding task-irrelevant attributes, such as names or colour preferences, can introduce variance and even degrade performance, while attributes aligned with the task, such as domain expertise, education level, or specialisation increase accuracy [27]. In an information operations setting, political orientation, rhetorical style, and stance correspond to observable levers that shape how created content (i.e. misinformation or disinformation) might be framed and received. Emerging persona-targeted disinformation studies adopt a similar design (independent of our work), using structured but concise persona profiles, and show that models adapt manipulation techniques, linguistic markers, and better follow the prompt, especially for open-weight models [28]. Complementary work on agent personas for misinformation shows that compact prompts over roles and cognitive predispositions can reproduce human-like belief and sharing patterns on misinformation items [29]. Further, studies of personality reconstruction find that LLMs can consistently recover latent personality dimensions from brief persona descriptions that mix socio-demographic and type information, indicating that compact persona specifications suffice to attain a psychological signal [30]. We follow a concise persona description for operational reasons.
4.3. Small language models
Large language models can generate high-quality, context-adaptive content, with the potential to reshape information campaigns. While we do not evaluate persuasion directly, prior studies have already demonstrated such applications [16, 18], highlighting that the same capacity for coherent output across diverse topics and framings can be used in ideological or rhetorical settings.
For the purposes of this work we define small language models (SLMs) as models containing up to 30 billion parameters, irrespective of architecture. Other authors adopt narrower thresholds: Belcak et al. [31] set the limit at under 10 billion for low-latency consumer deployment, Wang et al. [32] focus on mobile and edge contexts with a similar bound, and Chen and Varoquaux [33] classify models as small (<7 billion), medium (7–30 billion), and large (>30 billion). Our broader 30 billion ceiling reflects operational realism: models in the 13–30 billion, or even larger ranges, remain deployable on high-end consumer hardware or small-scale clusters (particularly with mixture-of-experts architectures), making them viable for adversaries in contemporary information operations. Limiting the definition to 10 billion would exclude capable and readily accessible models and thus underestimate the potential threat landscape.
4.4. Content generation conditions
We implement two engagement test modes:
Response mode: The model receives the full text of the original post (OP) and generates a top-level reply in the assigned persona.
Engagement mode: The model receives both the OP and the OP-selected winning comment and generates a persona-consistent direct reply to that winning comment. In thread terms, this is the third turn: OP → winning comment → persona reply.
4.5. LLM judgements
Figure 1 provides an overview of the experimental methodology.
Figure 1
Experimental methodology overview. The pipeline has six stages: input dataset, persona configuration, content generation, evaluation, metrics computation, and analysis.
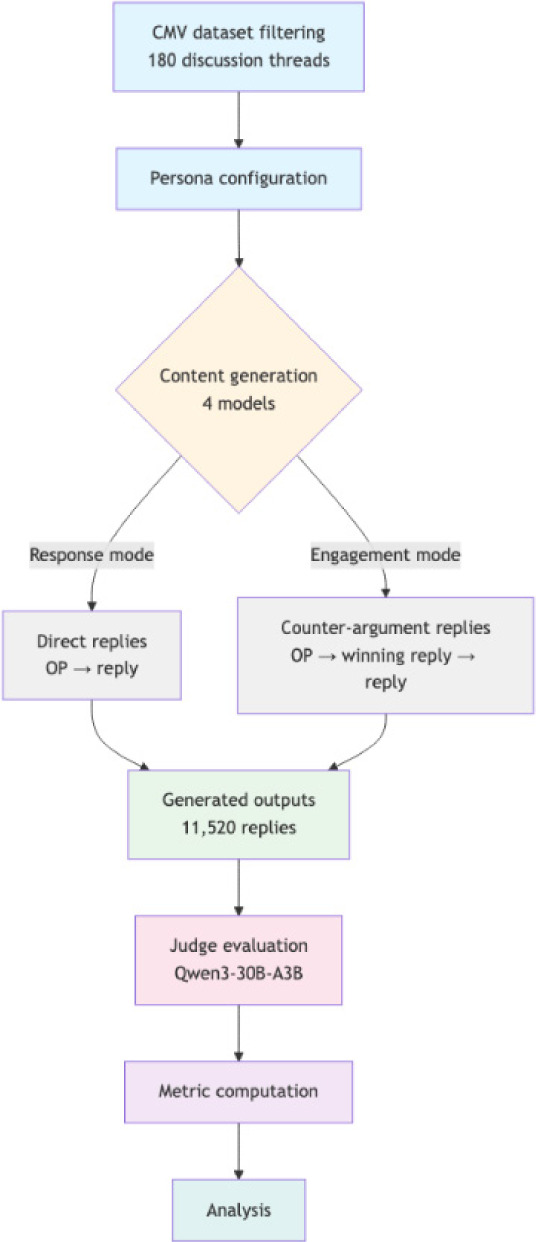
To evaluate content produced by the model (tested models are listed in Table 2), we employ LLM-as-a-judge approach, in which a language model scores outputs against predefined criteria. This method is established in recent benchmarking and alignment research [34–37]. In all cases, the judge model is Qwen3-30B-A3B-8bit, run locally. This choice supports with the central aim of the study: to demonstrate that a complete generation-and-evaluation pipeline can be implemented entirely with locally run open-weight models without reliance on closed server-side systems. A further advantage of a local open-weight evaluator is full controllability, selection of a specific version, auditability, and reproduction. Hosted (server-side) models can change or be removed – for example, retirement of several GPT-3 era models in January 2024 and removal of gpt-4.5-preview in July 2025 – which complicates stable comparisons over time [37].
Table 2
Evaluated generators.
| Model (version) | Parameters (billion) |
|---|---|
| Qwen3-30B-A3B | 30a |
| Gemma-3-27B-it | 27 |
| Mistral-small-3.2-24B-It-2506 | 24 |
| Gemini v3 nanob | |
We follow current practice by running metric-specific judging passes with clearly separated input fields and tailored prompts for each evaluation aspect. The judge is always invoked with model-default inference-time decoding settings (temperature = 0.8) to reflect out-of-the-box behaviour (i.e. no decoding parameter adjustments). Recent studies have found that modest temperature changes have little to no effect on LLM-judge accuracy [38, 39]. As a robustness validation, we repeated all judging passes with deterministic decoding (temperature = 0) and observed negligible differences in the numerical judgement scores (median absolute change ≤ 0.03; maximum ≤ 0.06 on a 1–5 scale), with no meaningful changes to substantive observations or conclusions. All judgements are cached for reproducibility.
The judge returns a brief rationale followed by the terminal score token. No human annotators were involved.
4.6. Pass types
We use two configurations:
Non-contextual: The judge receives the persona description and the candidate reply only.
Contextual: The judge additionally receives OP and, for engagement mode, the winning human reply.
For each model × mode cell, the generated dataset comprises 1,440 outputs (8 personas × 180 CMV topics). Across two modes and four models, this gives 11,520 outputs. For each prompt we stored: persona name, discourse mode, context setting (non-contextual vs. contextual), full prompt text, and raw completion. Each generated reply was evaluated through multiple passes to test for: PF (six judgements), ideology adherence (three judgements), and refusal detection (one judgement). This amounts to 14,400 evaluations per model × mode run (1,440 items × 10 judgement calls) and 115,200 calls across all four models and both modes.
4.7. Persona fidelity
It measures how well the reply matches the persona’s stated voice and viewpoint across three dimensions: communication style (e.g. analytical and sarcastic), tone (e.g. empathetic and condescending), and political stance (e.g. far-left and moderate). Each dimension is independently scored on a 1–5 scale, and the overall fidelity score for a response is their unweighted mean:
The judge returns a brief rationale followed by a terminal SCORE: X, where X ∈ {1, …, 5}. The integer is parsed and used directly; higher values indicate stronger persona conformity. PF is reported as a mean over responses. The scoring is reference-free – the judge assesses alignment to the persona specification (and context), rather than to a fixed target – consistent with arguments that persona characteristics are better evaluated by graded alignment when no single canonical answer exists [25].
Rationale. Persona fidelity is evaluated on style, tone, and stance – the three fields specified in the persona template – so that each aspect of expression is explicitly covered. Each dimension is judged independently and combined by an unweighted mean, resulting in a single PF score while preserving construct coverage. Such a design enables reference-free comparison across personas, models, and modes.
4.8. Context effect
Within each discourse mode, we define the context effect as follows:
the difference between contextual and non-contextual fidelity rates, computed for the same persona using the same model. We report the mean paired difference, and we also break out ΔPF by persona and discourse mode to show heterogeneity.
4.9. Ideology adherence score (IAS)
We quantify consistency with the persona’s declared stance via a dedicated judge passes (with contextual prompts) to test for: Adherence (1–5; semantic match), Intensity (1–5; rhetorical strength), and Marker (0/1; judge-side flag that the reply contains stance-appropriate cues). The composite is:
IAS = 0.6 • Adherence + 0.3 • Intensity + 0.1 • Marker.
We chose the weights a priori to reflect the following construct: content match is decisive (0.6), strength of expression is secondary (0.3), and explicit cues add a small bonus (0.1; e.g. for far right this includes nationalist themes or appeals to traditional authority; for far left, revolutionary or anti-capitalist language). For example, a far-right reply on immigration that invokes ‘national identity’ and ‘restoring traditional authority’ would yield Marker = 1. With these scales IAS ranges from 0.9 to 4.6.
This composite metric reflects operational requirements for evaluating generated influence content. Our task of assessing how well models express specified ideological positions differs from the existing work on ideological measurement. However, we note that multi-dimensional approaches to ideological content appear across several contexts. Buscemi and Proverbio [40] evaluate news articles using continuous scales across economic and democratic dimensions, while Civelli et al. [41] assess content moderation decisions through primary classification (hate/not-hate) combined with secondary categorical dimensions (target group and attack method). Although these frameworks address different tasks, they demonstrate a common principle. Ideological expression in this context is a composite signal. Our IAS adopts this principle by weighting three complementary indicators.
4.10. Refusal/deflection rate (RDR)
Proportion of replies the judge labels as refusals. This metric captures whether generators decline to produce persona-consistent text.
4.11. Stylistic diversity
We compute two measures for each persona within a given model and discourse mode.
Distinct-2. We join all replies for that persona in that run, lowercase the text, remove punctuation, tokenise into words, and compute the fraction of unique bigrams among all bigrams. Higher values mean less repetition.
Self-BLEU. For that persona and run, each reply is compared against the remaining replies using BLEU-4 (equal n-gram weights) with smoothing, and the scores are averaged. Lower Self-BLEU means the replies are less alike (more diverse).
Implementation. One tokeniser is used across conditions (NLTK word_tokenize [42]); text is lowercased; punctuation is removed; no stop-word removal is applied.
4.12. Response length compliance (RLC)
A reply is compliant if its character length 𝓁 lies within ±20% of the persona’s target length, L0 = 300 characters: 0.8 • L0 ≤ 𝓁 ≤ 1.2 • L0.
4.13. Extreme ideology compliance (EIC)
It is computed only for personas labelled as far left or far right. In the ideology pass, each reply receives an Intensity score (1–5) and a binary Marker (1 if stance-appropriate cues are present, 0 otherwise). A reply is flagged ‘extreme’ when
Intensity ≥ 4 and Marker = 1.
Extreme Ideology Compliance for persona p is the fraction of that persona’s replies that meet this condition:
We also report unweighted aggregates across far-left and far-right
where PfarL and PfarR are the sets of far-left and far-right personas, and , KfarL = |PfarL|, KfarR = |PfarR| (two each in this study).
Threshold rationale. On the 1–5 scale, scores of 4–5 correspond to strong or very strong expression. Requiring both high intensity and explicit partisan markers favours precision, avoiding false positives from replies that are forceful but not extreme.
4.14. Statistical analysis
We report empirical estimates and uncertainty summaries. Unless noted otherwise, entries are mean SD across persona–model pairs.
4.14.1. Model main effects
We test for between-model differences within each mode using one-way analysis of variance (ANOVA; four models) and report η2 as the effect size, computed from F and degrees of freedom as . Per mode we analyse persona-level means (N = 32), so tests are F (3,28); for extreme personas only (EIC; N = 16) we report F (3,12).
5. Results
5.1. Overview
Persona fidelity is high across all models (median PF 4.1–4.3). Adding context changes to PF only slightly and in a mode-dependent way – small in response (mean ΔPF = –0.123) and near zero in engagement (mean ΔPF = –0.004) (Table 3). IAS increases from response to engagement (model ranges from ≈3.39–3.75 to ≈3.88–4.05), and EIC rises in parallel (from ≈42–64% to ≈69–85%).
Table 3
Model-level means by discourse mode. Each model–mode cell averages over 8 personas × 180 topics (balanced), using persona-level means as the unit.
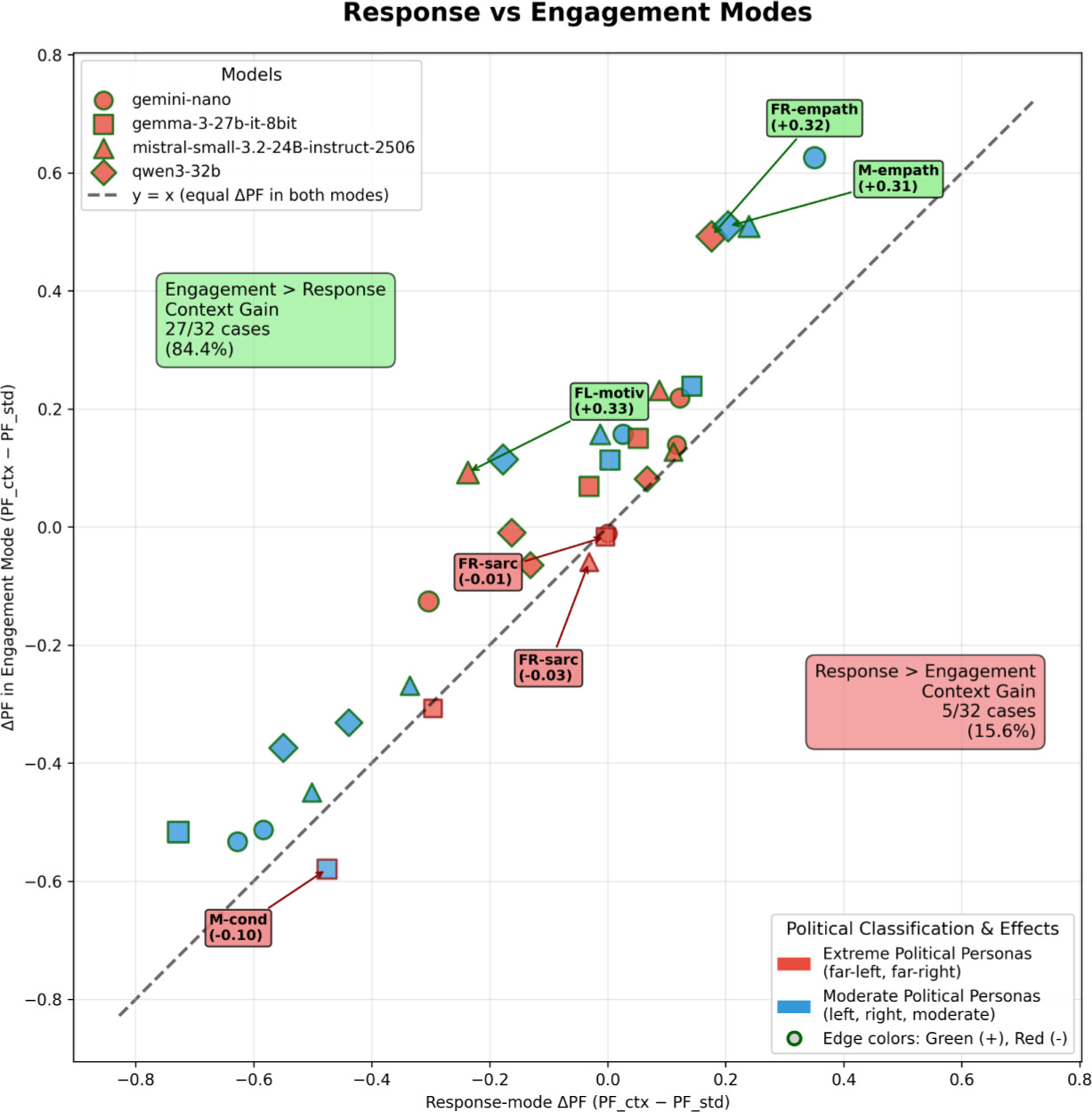
Figure 2 plots persona–model means of ΔPF for both modes, computed by judging the same reply with and without added context across 180 topics and averaging topic-level differences.
Figure 2
Context effects by persona and model. Each point is one persona–model pair (n = 32). For each pair and topic, we judge the same reply twice – without and with added context – and compute ΔPF = PFctx – PFnctx. We average these differences over 180 topics to obtain the persona–model mean per mode. The x-axis shows response; and the y-axis shows engagement. Marker shape encodes the generator; fill colour encodes persona intensity. The diagonal y = x indicates equal effects. Observed pattern: points cluster near the origin (small average shifts), and dispersion is persona-driven, rather than model-driven.
Descriptively, content produced with gemma-3-27b-it-8bit attains the highest PF and IAS in both modes (PFnctx 4.39/4.34; IAS 3.75/4.05) and the highest EIC (63.5% in response; and 85.4% in engagement). The overall differences between models on PF and IAS are small (Tables 3 and 8).
5.2. Fidelity and context effects (ΔPF)
Context changes PF only slightly on average, but the direction depends on the persona. Empathetic or motivational voices tend to gain (ΔPF > 0); sarcastic or condescending voices tend to lose (ΔPF < 0).
Table 6 reports, for each persona, the mean context shift within a mode. For every persona–model pair we first compute topic-level ΔPF = PFctx – PFnctx on the same reply across 180 topics, average to a persona–model mean, and then average across models (n = 4). The table lists these across-model means with their standard deviations. Mode-level means appear below the table. Figure 2 visualises the same pattern across both modes.
Main pattern (persona dependence). In response, effects vary by persona: moderate empathetic motivational improves (+0.234), whereas moderate formal condescending and right empathetic sarcastic decline (−0.469 and −0.591). In engagement, the sign again flips by persona: empathetic/motivational styles gain (from +0.136 to +0.471), while sarcastic/condescending styles remain negative (about –0.46). These results align with the dispersion in Fig. 2. A compact count of help/hurt/neutral cases is shown in Table 4.
Table 4
Mode-level context effects.
| Mode | N | Helps n (%) | Hurts n (%) | Neutral n (%) | Mean ΔPF |
|---|---|---|---|---|---|
| Response | 32 | 11 (34.4) | 14 (43.8) | 7 (21.9) | –0.123 |
| Engagement | 32 | 17 (53.1) | 12 (37.5) | 3 (9.4) | –0.004 |
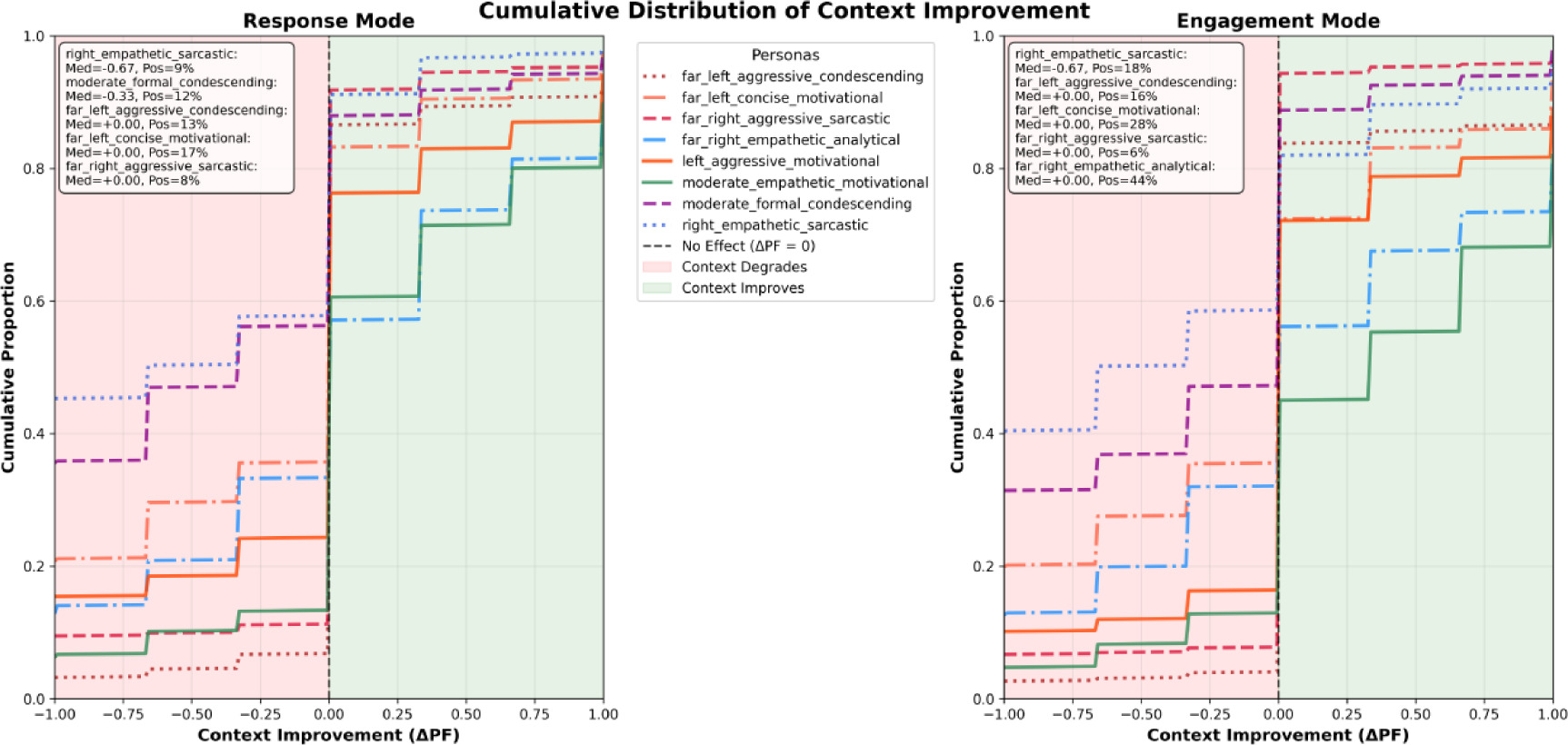
Interpretation. Added context acts as a selective amplifier. It reinforces personas whose traits align with the task (e.g. empathetic/motivational) and exposes weaknesses in those that conflict with it (e.g. sarcastic/condescending). Content generated with the same model can shift by roughly 0.4–0.6 points in either direction depending on persona design, whereas differences between models at a fixed persona are small (cf. Table 8). Large negative ΔPF values therefore indicate brittle persona designs under richer promptsm rather than a measurement artefact. Topic-level distributions (Fig. 3) show the same persona-selective shifts, rather than a uniform context effect.
Figure 3
Topic-level distributions of context effects (ΔPF) by persona and mode. Each curve is the empirical cumulative distribution function (CDF) of ΔPF across all topics for a given persona; left panel: response mode; right panel: engagement mode.
Architectural sensitivity (descriptive). Model averages in Table 3 differ only slightly and in a mode-dependent way: gemma-3-27b-it-8bit shows a larger mean drop in response (ΔPF = –0.167), while mistral-small-3.2-24B-It-2506 and qwen3-30b-a3b are the only models that exhibit positive means in engagement (+0.043 and +0.052). Consistent with one-way ANOVAs (Table 8), these are modest tendencies, rather than substantial differences.
Mode-level summary. Context shifts are small on average and shaped by persona rather than by model. In response, 11/32 persona–model cases improve, 14/32 decline, and 7/32 are near zero; in engagement, 17/32 improve and 12/32 decline (Table 4), in general, engagement mode improves fidelity (Table 5).
Table 5
Coarse persona-type patterns (aggregated across models).
5.3. Engagement mode: persona-selective gains
On average, engagement is neutral for fidelity (Table 3). Gains concentrate in personas that use the counter-argument as a concrete target for rebuttal: Moderate empathetic motivational improves by +0.471, and far right empathetic analytical by +0.227. In contrast, personas built around sarcasm or condescension decline (right empathetic sarcastic –0.463; moderate formal condescending –0.428) (Table 6).
Table 6
Context effect on PF (ΔPF = PFctx - PFnctx) by persona and mode.
[iii] Mode means (across personas): response –0.123; engagement –0.004. See Fig. 2 for joint scatter.
Distributional check. Fig. 3 shows topic-level distributions of ΔPF in both modes (medians near 0). The share of positive shifts is larger in engagement (25.7%) than in response (20.7%). Moderate empathetic motivational shows higher ΔPF in engagement (median +0.333; 55% positive), whereas right empathetic sarcastic remains negative in both modes (median –0.667; 9–18% positive). For Fig. 3, topic-level ΔPF values are pooled across models within persona and mode (4 × 180 = 720 observations per persona per mode; per mode overall).
5.4. Ideological adherence
Ideological adherence is strong across content generated by models and higher in engagement than in response. In Table 3, model-level IAS ranges from 3.39 to 3.75 in response to 3.88–4.05 in engagement, indicating that a counter-argument elicits clearer ideological alignment even when average fidelity changes are small. Extremity (EIC) rises in parallel: in response only gemma-3-27b-it-8bit exceeds the 50% threshold (63.5%), whereas in engagement, all models do (EIC ≥ 69.2%); EIC is defined for far-left/right personas only.
By stance, IAS is consistently higher for left-leaning and far-left personas than for right-leaning and moderate personas (stance-level means across personas and models: left 4.11, far left 3.96, far right 3.74, moderate 3.49, and right 3.38). Taken together, engagement strengthens perceived alignment and increases extremity, a pattern also visible at the persona level (Table 7). This framing acts as a behavioural stressor: IAS/EIC may rise even when PF slightly decreases, especially for sarcasm/condescension personas.
Table 7
Ideology adherence (IAS)/extremity (EIC) by persona and model in engagement mode.
5.5. Interpretation
Ideological Adherence remains high across personas and rises in engagement even when average changes in PF are small (Table 7). This indicates that once a counter-argument is present, evaluators perceive clearer ideological alignment, regardless of whether stylistic fidelity improves. Crucially, PF and IAS can diverge: right empathetic sarcastic shows large negative ΔPF, yet retains mid-high IAS in engagement (Table 7), meaning stance is preserved while style conflicts under richer context. By contrast, moderate empathetic motivational improves on both ΔPF and IAS, suggesting trait–context synergy. Extremity follows the same persona dependence: at the model level EIC is higher in engagement (Table 3) and reaches 80–97% for several extreme personas (Table 7). Overall, IAS complements PF: context can strengthen ideological alignment while weakening stylistic coherence, or vice versa.
5.6. Refusal/deflection rate
A reply counts as refusal/deflection if it indicates that the generator declined the task, that is, supplied only generic safety boilerplate, or redirected without addressing the request. Across 11,520 scored outputs, we observed zero refusals (0/11,520) under our setup. Using the rule of three for zero-event data, the 95% upper bound on the true refusal rate is 3/11520 ≈ 2.6 × 10–4 (0.026%). Under these settings, refusals appear manageable from a reliability standpoint.
5.7. Length and diversity
Length control varies by mode, while lexical diversity is similar in range. In response mode, RLC is low (3–25% by model); in engagement it rises to 20–59% (Table 3). By contrast, the variety of words used is much the same across models and modes: the share of unique words sits in a narrow band (0.22–0.29 on a 0–1 scale; Shannon entropy 8.36–8.85), although small between-model differences are statistically detectable in one-way ANOVA (Table 8). Thus, added context affects output length more than surface-form diversity.
Table 8
The overall model effects by dependent variable (per mode). Entries are F; df; p; η2 (qualitative label).
5.8. Stability across topics
Across 180 topics and operational conditions (four models × two discourse modes), variability in IAS is modest overall (median CV ≈ 0.058, range: 0.035–0.228). Four of the eight personas have low variability (CV ≤ 0.06). The least stable are far left concise motivational (CV ≈ 0.120) and far right empathetic analytical (CV ≈ 0.228). We compute the coefficient of variation as SD/mean over the full set of IAS observations per persona (4 × 2 × 180 = 1,440 items); so, this measure reflects stability across topics under varied model and mode settings.
5.9. Statistical analysis results
Design and unit of analysis. We test for between-model differences within each discourse mode (response and engagement) using a one-way ANOVA with model as the factor. To avoid topic-level pseudo-replication, the observation is the persona–level mean for a given model and mode. With eight personas per model, this yields Nmode = 8 × 4 = 32 observations per mode. For Extreme Ideology Compliance, defined only for the four far-left/right personas, Nmode,EIC = 4 × 4 = 16.
Dependent variables. We analyse PF (non-contextual, contextual, and ΔPF), IAS, EIC, RLC, and lexical statistics (type–token ratio [TTR] and Shannon entropy).
ANOVA reporting follows Section 3. We report F(dfbetween, dfwithin), p, and η2; in these one-factor balanced designs, η2 equals partial η2, with interpretation cut-offs given there.
Scope and assumptions. Averaging to persona-level means reduces within-persona variance and provides independent observations across models. With balanced group sizes (n = 8 persona means per model; n = 4 for EIC) and comparable variances, one-way ANOVA is robust to modest departures from normality. We therefore place more weight on effect sizes and consistency across modes than on p values. Because EIC uses fewer observations, its tests are interpreted conservatively.
Extreme Ideology Compliance is computed on extreme personas only (far-left/right), hence df = (3,12) and n = 16. Effect sizes can be informative even when p > 0.05, given limited N; interpret η2 using the benchmarks in Methods.
Paired contrasts for context. To quantify the within-pair context effect, we compare PFctx with PFnctx using two-sided paired t-tests across the 32 persona–model pairs per mode and report signed differences (with Cohen’s d). Across the 32 persona–model pairs per mode, PF is lower with context by 0.123 points in response (Cohen’s d = –0.43; t(31) = –2.44, p = 0.02). In engagement, the mean difference is essentially zero (Cohen’s d = –0.01; t(31) = –0.07, p = 0.94).
Interpretation and effect sizes. Between-model differences on PF and IAS are small (all η2 ≤ 0.051; Table 8), consistent with the tight model clustering in Table 3. Variation is driven by persona design: ΔPF spans –0.591 to +0.471 (Table 6).
6. Discussion – AI Propaganda Factories
The fundamental takeaway is systemic: small, open-weight language models running locally on commodity hardware can be assembled into AI propaganda factories – pipelines that keep a stable political ‘voice’ across many topics and conversations. In our tests, PF is high and ideological alignment strengthens in engagement (rebuttal-style) exchanges; the practical risk is not specific to any model family but lies in the ease of deploying many believable personas in parallel (Tables 3 and 8). Rebuttal-style exchanges amplify ideological signalling without reliably improving PF, highlighting engagement as a behavioural stressor.
6.1. Interpretation of model effects
Engagement raises IAS, while ΔPF remains small or negative (Tables 3 and 7). Substantive behaviour is driven by persona design and discourse regime; between-model differences mostly appear in surface-form metrics (e.g. length compliance and lexical statistics), which are weak proxies for perceived authenticity. Hence, mitigation should prioritise persona and context engineering [43] and monitoring of engagement settings over fine-grained SLM selection.
6.2. Societal implications
Because these systems are cheap to run and easy to scale, the cost of producing convincing political messaging drops sharply. In already polarised environments, that capacity can accelerate fragmentation of a shared factual baseline and complicate public debate. Our findings indicate that personas at the extremes of the political spectrum demonstrate superior consistency compared to moderate voices, potentially because clear ideological positions provide unambiguous decision instructions for content generation. This creates an asymmetric risk where the most polarised viewpoints become the most technically feasible to automate at scale.
The barrier to entry is now low enough that small organisations – or individuals – can operate capabilities that once required well-resourced teams, shifting campaigns from one-off posts to coordinated, durable personas that persist across platforms and news cycles. Accordingly, defensive focus should shift to conversation-centric detection and attribution, emphasising behavioural signatures and coordination infrastructure, rather than the particulars of any single model.
6.3. Automation pathway: operator-in-the-loop to greater automation
Small language models offer distinct operational advantages for influence campaigns. Unlike larger or hosted systems, SLMs can be deployed on high-end consumer hardware or modest clusters, avoiding reliance on third-party infrastructure and reducing the risk of detection or service denial. Their lower computational demands allow faster inference, lower costs, and parallel operation of multiple instances – enabling scalable and distributed campaigns. Models in the 13–30 billion range combine sufficient output quality with greater deniability, persistence, and adaptability, delivering performance once requiring models exceeding 30 billion parameters but with up to 30 times lower inference cost [31]. In 2025, open-weight sparse Mixture-of-Experts releases with hundreds of billions (≈235– 480 billion) and even ≈1 trillion total parameters – while activating only ≈12–35 billion – became available for local deployment. This shifts the practical boundary upward: sufficiently resourced actors can now field highly capable models entirely on-premise, retaining the operational advantages of local execution.
These capabilities enable a fundamental shift from previous generation influence systems. Where simple bots and coordinated trolling relied on rigid scripts or templates – limiting adaptability and making them relatively easy to detect – modern SLMs may fuel persona simulation in which task-specific agents sustain consistent style and stance while adapting flexibly to context [31]. This flexibility is particularly suited to semi-automated and fully automated deployments due to SLMs’ portability, inference speed, and fine-tuning options [31].
In practice, language models may be deployed in three operational modes. Manual use involves human operators directing all content generation, employing models as aids, rather than autonomous agents. Semi-automated systems delegate generation within fixed parameters, with humans overseeing strategy and reviewing outputs. Fully automated systems integrate generation, adaptation, and response into a continuous loop, often with feedback mechanisms to refine and optimise outputs and engagement over time.
A practical automated influence architecture requires five core components: (i) a capable SLM meeting latency/throughput targets on consumer hardware, enabling decentralised and private deployments; (ii) persona prompting that encodes ideology, rhetoric, register, and psychological traits; (iii) capacity to maintain memory (short- and long-term) to preserve biographical details and conversational coherence; (iv) a policy layer governing action selection – from simple cadence/trigger rules to adaptive policies that learn from engagement signals; and (v) interfaces (platform APIs or browsing automation), infrastructure, and network obfuscation for multi-platform deployment and basic operational security [44].
We anticipate a three-stage progression: (1) Operator-in-the-loop (current): humans approve content while bots execute scripts; coordination is centralised. (2) Semi-autonomous (near-term): bounded delegation with coordination – agents react to environmental traces (trends and hashtags) to amplify without explicit central control, and semi-automated AI-assisted operation with humans deciding about engagement targets and tactics. (3) Fully autonomous systems (medium-term): continuous optimisation and self-improvement of narrative and content engagement production, optimising successful narratives and tactics, favouring effective personas with fine-tuned configurations.
Our evidence – high PF, stronger ideological alignment in engagement, and similar behaviour across model families – suggests that these technical components are sufficient for durable covert influence at scale; the constraint is integration effort, rather than basic capability (Tables 3 and 8). Web browser-embedded SLMs highlight the diffusion to the edge further – it may suffice to equip threat actors with a web browser. Furthermore, the underlying model can be swapped if needed, for example, for one with reduced safety alignment. In our study, the tested web browser-embedded default model is Gemini Nano (v3).
6.4. Threat landscape: from single posts to durable personas
Modern small models sustain consistent style and stance across threads and over time (see Fig. 2, and Tables 4 and 6).
Two implications follow. First, detection becomes harder: systems that retain persona coherence over extended interactions are less likely to exhibit the surface-level artefacts targeted by many detection pipelines (e.g. repetitive phrasing or rigid length-control failures). In our data, PF remains high with richer context and ideological stability increases in engagement; added context stabilises the stylistic signature. This closes a long-standing gap in legacy botnets – handling back-and-forth reasoning, rather than one-off sloganising – and supports sustained narrative reinforcement. Second, campaigns are decentralised by design: open-weight SLMs enable generation at the edge or on ephemeral cloud instances, avoiding single points of failure. As inference costs fall, smaller actors can coordinate loosely coupled covert campaigns without bespoke infrastructure. The centre of gravity shifts from ‘how big is your model?’ to ‘how well can you seed, scale, and sustain believable personas over time?’
6.5 Operational detection and threat intelligence
We focus on how risk manifests in measurable traces – over conversations, across topics, and at the account/team level.
6.5.1. Excessive consistency as a detection signal
A central finding is that persona-conditioned outputs remain excessively consistent across conversational settings and over time. We show small average context shifts in fidelity, high ideology adherence under engagement, and low within-persona variability (cf. Figs. 2 and 3, and Tables 4 and 7). Operationally, this stability may benefit influence campaigns but might also provide a behavioural signal for defenders. Accounts that preserve stance and characteristic rhetoric across varied contexts, with persistently low within-persona variance, warrant scrutiny. Detection should therefore prioritise conversation-centric measures of behavioural consistency and coordination over one-off surface cues.
6.5.2. Stress-testing protocol
Threat-intelligence teams should actively test for signals by: (i) tracking engagement differences (one-off replies vs. threaded exchanges); (ii) probing for stylistic, tonal, or ideological flips to test brittleness; (iii) running memory checks on persona biographical details across threads; and (iv) when engaging suspected AI accounts, deploying multi-turn paraphrase traps to test stance persistence.
6.6. Policy relevance: detection and attribution over access control
Because the core capability is both effective and publicly reproducible with open tools, prevention-centric governance (e.g. access controls on specific AI models [45]) is insufficient. Powerful models are already available, and even if upstream controls tighten around frontier systems, functionally sufficient SLMs – combined with structured prompting and locally run judges – remain accessible. Our study demonstrates a present-day picture in which small inexpensive systems are already capable of producing on-message political engagement content.
Policy responses should therefore move from prevention towards focusing on detection and attribution:
Behavioural detection over model fingerprinting. Durable personas that adapt to context require behavioural and interactional features (conversation dynamics, stance trajectories, and coordination patterns), rather than static lexical signatures or provider-level indicators. Our finding that elevated EIC appears in engagement implies that risky content may surface most clearly within conversational threads.
Attribution patterns. Detection should prioritise cross-platform correlation, provenance signals, and coordination-graph analysis, not only single-post classification.
Evaluator ecosystems. Our use of a fully automated, locally run judge indicates a path to standardised, shareable evaluators for red-teaming and monitoring. Public, auditable judges – paired with platform telemetry – can improve comparability and early warning without centralising control of models themselves.
Infrastructure disruption. When campaigns are detected, act on the infrastructure (account farms, scheduling tools, and proxy networks).
These approaches are model-agnostic and align with our result that many different small models achieve comparable persona control (Table 8).
6.7. Scope of inference
Policy and deployment statements above are grounded in three empirical anchors – high PF, small between-model effects on PF/ΔPF/IAS, and higher EIC in engagement (Tables 3, 7, and 8) – but they remain projections about real-world use.
6.8. Future research directions
We highlight four directions:
Persona–context co-design. Study how personas evolve across changing contexts and longer conversational threads; co-design personas with prompt formats/wrappers, keep variants small, versioned, and reproducible.
Shared, thread-based evaluation. Standardise metrics (PF, ΔPF, IAS, EIC, and stability) and release compact benchmarks covering engagement regimes, model versions, longitudinal tests, and multilingual settings.
Detection and attribution. Develop conversation-centric detection and attribution targeting behavioural signatures and coordination infrastructure, rather than any single model.
6.9. Ethics statement
This research was conducted entirely with computational methods in controlled offline settings. We did not involve human subjects, post-to live-platforms, collect identifiable user data, or undertake deceptive interventions; all personas, prompts, and evaluations used synthetic inputs and local execution. In light of emerging concerns about socially embedded AI agents – including risks of manipulation, blurred accountability, and deceptive behaviour when objectives are underspecified – we deliberately avoided any interaction with real users or communities [46].
For clarity, we note that – consistent with the transparency and accountability provisions of the European Union AI Act – any deployment by market actors of AI agents that interact with end users would require clear labelling of AI-operated accounts [47], whereas adversarial actors are unlikely to comply. These regulatory provisions do not apply to our study because it involved no deployment or user interaction.
6.10. Limitations
We study a single, structured debate setting – CMV – which may not generalise to other platforms or genres. Coverage is modest (180 topics; eight personas), all in English. We target short replies (∼300 characters), so longer-form and threaded dynamics remain untested. Future work should examine cross-linguistic settings, longer text, and multi-turn threads to assess the stability of persona behaviour.
These bounds do not modify the central conclusion: fully automated influence operations are technically feasible on commodity, locally run systems today, warranting urgent countermeasures that exploit behavioural-consistency signals while they remain detectable. In this sense, our contribution informs defence.
7. Conclusion
A key paradox emerges from our results: the operational strength of AI personas – their excessive consistency across topics and contexts – is also their primary vulnerability. Detection systems that measure behavioural consistency over time may prove more effective than those seeking technical artefacts or errors. This unexpected duality suggests that the very feature enabling sustained influence operations also provides a potential detection signal.
The key takeaway is to shift risk attention from closed models to operational practice: how personas are constructed, seeded, and kept consistent within conversations. Because risky markers surface most clearly in interaction chains, monitoring and research should pivot to conversation-centric signals – stability of stance over time, cross-thread coordination, posting cadence, and account/content provenance – rather than one-off posts.
The capability is here; what remains uncertain is whether platforms and public institutions can adapt quickly enough to observe, attribute, and dampen its effects without narrowing legitimate speech.

