
1. Introduction
In today’s digitally connected world, cybersecurity has become more important than ever. As networks grow larger and more complex, they also become more vulnerable to increasingly sophisticated cyberattacks. Traditional systems, such as rule-based intrusion detection tools, often struggle to keep pace with evolving threats. Machine learning (ML) has emerged as a promising solution, offering the ability to learn from past patterns and intelligently identify suspicious activity in real time [1, 2]. However, relying on a single algorithm often leads to limited performance, as each model has its own strengths and weaknesses. For example, support vector machines (SVMs) are effective for structured data but can miss non-linear relationships [3, 4]. Deep neural networks (DNNs) are powerful but require extensive data and training time [5, 6]. Random forests are robust to noise but can introduce bias if not tuned properly [7]. The challenge is to develop systems that balance these differences to make smarter, more reliable decisions, especially in high-stakes environments like information security. The goal of our study is improving detection accuracy, reduce false alerts, and build a system that works well across different kinds of attack patterns. By testing this ensemble method on well-known cybersecurity datasets like NSL-KDD and CICIDS2017 [8], we aim to show how combining models can lead to better and more consistent results. Table 1 summarises recent relevant studies on intrusion detection, highlighting their methods, contributions, and limitations.
Table 1
Recent relevant studies.
| Author(s) Year | Method | Main contributions | Limitations |
|---|---|---|---|
| Paes et al., 2025 [1] | Supervised ML (various) | Compared classical ML algorithms for attack detection | Focused on single classifiers; limited generalisability |
| Benmalek and Seddiki, 2025 [2] | PSO-enhanced ML/DL for internet of things (IoT) | Improved optimisation for intrusion detection in IoT | High computational cost; narrow IoT context |
| Kachavimath and Narayan, 2025 [5] | Hybrid DL with feature selection | Strong performance for DDoS detection in SDN | Focused on a single attack type and environment |
| Gamal et al., 2024 [9] | LSTM-RNN | Improved intrusion detection in drone networks | Application-specific; not tested on general datasets |
| Garouani et al., 2025 [10] | Stacked ensemble (XStacking) | Proposed explainable ensemble framework | Not applied to intrusion detection datasets |
| Masud et al., 2025 [11] | Hybrid moving target defence | Enhanced IoT security using hybrid models | Tailored to IoT; lacks cross-dataset validation |
The existing works demonstrate that both single models and ensemble approaches can be effective in specific contexts [12, 13]. However, most studies either (1) apply single algorithms with limited robustness, (2) design ensembles restricted to homogeneous or two-model hybrids, or (3) validate their approaches on narrow or application-specific datasets. There remains a need for a heterogeneous ensemble framework validated across multiple benchmark datasets, capable of delivering balanced performance in terms of accuracy, recall, and robustness.
This study contributes to the field of intrusion detection in several key ways. First, we propose an ensemble framework that combines three diverse classifiers, Random Forest, SVM, and DNN, rather than relying on homogeneous ensembles or two-model hybrids commonly reported in prior studies. This diversity enables the system to capture a broader spectrum of attack patterns, including both structured and highly non-linear behaviours. Second, the authors evaluate the model across multiple benchmark datasets (NSL-KDD, CICIDS2017, and UNSW-NB15), thereby demonstrating its robustness and generalisability in varied traffic scenarios. Third, our comparative analysis highlights a practical trade-off: while individual models, such as logistic Regression, excel in raw accuracy, the ensemble achieves the strongest area under the curve (AUC) score, which is crucial for reliably distinguishing between benign and malicious traffic. Finally, by focusing on both detection accuracy and reduction of false alarms, this work addresses the pressing need for balanced, real-world applicable solutions in cybersecurity.
While ensemble learning has been studied in cybersecurity, most existing research either applies homogeneous ensembles (e.g. multiple decision trees) or focuses on two-model hybrids. Our approach builds on this foundation but advances it in three important ways. First, we employ a heterogeneous ensemble of three diverse classifiers, Random Forest, SVM, and DNN, designed to capture both linear relationships and complex non-linear attack behaviours. Second, we evaluate the model across multiple benchmark datasets to ensure robustness and cross-environment reliability, whereas many prior works are limited to single-dataset validation. Third, our comparative results reveal that while individual models, such as logistic regression, achieve slightly higher accuracy, the proposed ensemble offers the best AUC score, demonstrating a stronger ability to balance precision and recall and reduce false alarms. These advances underscore the contribution of this study in moving beyond the existing ensemble designs towards a more generalisable and practically useful intrusion detection framework.
2. Methods
The method shown in Fig. 1 takes a thoughtful, data-driven approach to this challenge by using ensemble learning to improve threat detection accuracy. It starts with gathering relevant security data and splitting it into training and testing sets, which help to ensure fair model evaluation. Then, multiple machine learning models – Random Forest, SVM, and DNN – are trained individually to recognise malicious patterns. By combining their predictions, the system can make more balanced and reliable decisions about potential threats, reducing the chances of false alarms or missed attacks [14–16].
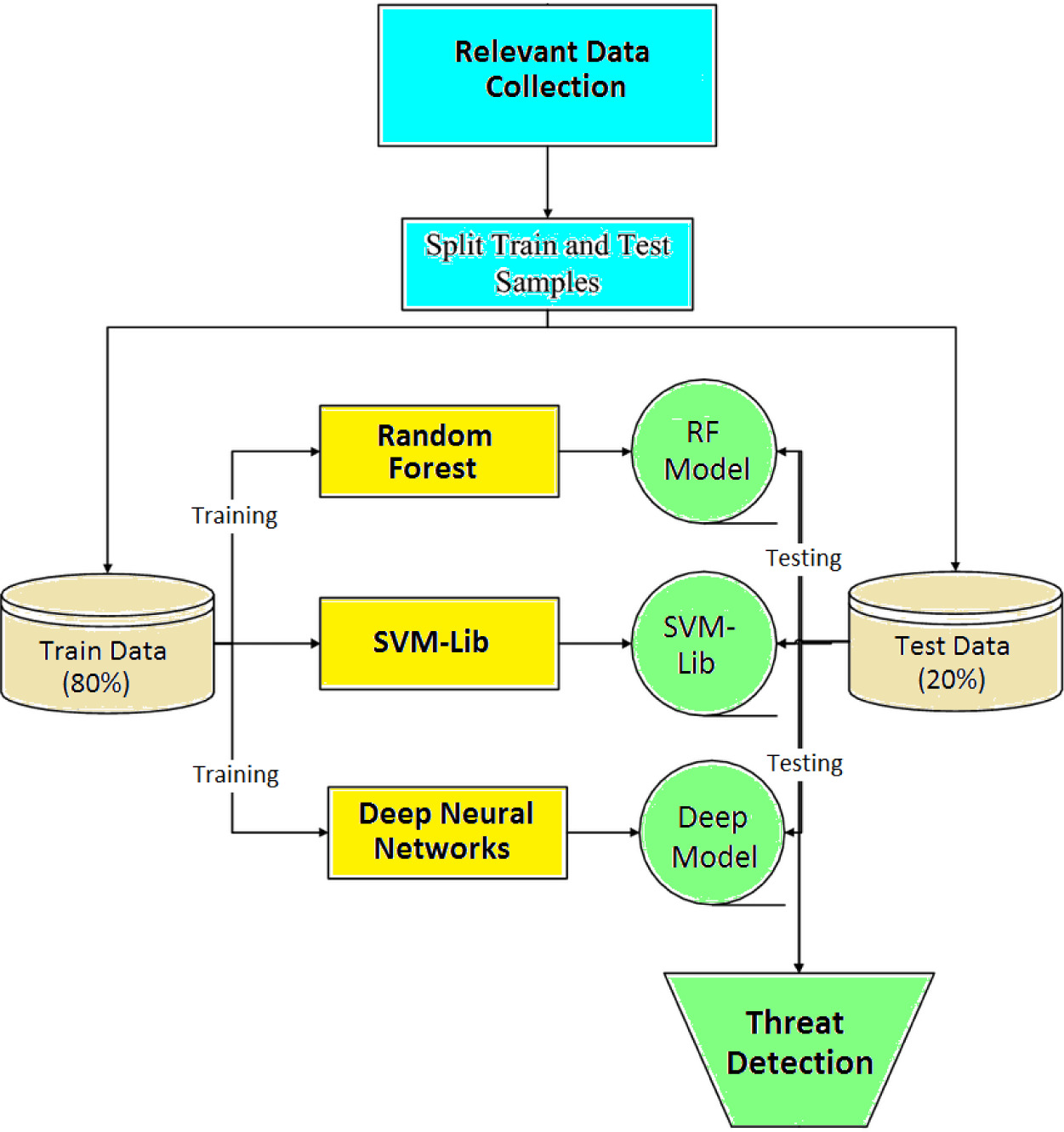
Procedures not directly relevant to the research question can be described briefly, but they should not be omitted.
2.1. Relevant Data Collection
The foundation of any effective threat detection system is high-quality and relevant data. In cybersecurity, this often involves collecting structured logs of network traffic, user behaviours, or system activities. Datasets like NSL-KDD, CICIDS2017, and UNSW-NB15 are widely used and contain labelled records that distinguish between normal and malicious activities. These datasets typically include features such as IP addresses, protocol types, connection duration, and packet statistics. Table 2 shows a simplified example of a dataset.
Table 2
The example of a dataset.
| Src_IP | Dst_IP | Protocol | Duration | Packet_Count | Label |
|---|---|---|---|---|---|
| 192.168.1.x | 10.0.0.5 | TCP | 20.3 | 45 | Normal |
| 192.168.1.x | 10.0.0.12 | TCP | 0.5 | 2 | Intrusion |
| 172.16.0.x | 10.0.0.7 | UDP | 300.1 | 560 | Normal |
| 192.168.1.x | 10.0.0.8 | TCP | 0.1 | 1 | Intrusion |
The table shows a simple snapshot of network activity that could be used to teach a machine learning model how to spot security threats. Each row represents a connection between two devices, with details like the source and destination IP addresses, the type of protocol used (like TCP or UDP), how long the connection lasted, and how many packets were sent. The last column tells us whether the activity was normal or suspicious. For example, connections that are extremely short and involve very few packets – like the ones labelled ‚Intrusion’ – could be the signs of a potential attack. Meanwhile, longer and heavier traffic like the UDP connection lasting for over 300 seconds is marked as normal. By learning from this kind of labelled data, a model can begin to recognise the subtle differences between everyday network behaviour and something that might be dangerous.
2.2. Split Train and Test Samples
To evaluate model generalisability, the dataset is split into training and testing subsets. Commonly, 80% of the data is used for training, while 20% is reserved for testing. This ensures that models learn from a substantial portion of the data and are then evaluated on unseen instances.
2.3. Model Training
In this stage, multiple machine learning models are trained separately on the training data. For this research, three types of classifiers are used: Random Forest [17], SVM [18], and DNN [19]. Each model learns to recognise patterns and behaviours that are commonly associated with either normal or malicious network activity. By using different algorithms, each model brings a unique way of understanding the data, which adds diversity and strength to the overall system.
Figure 2 provides a comprehensive overview of an ensemble learning approach designed for detecting threats in network traffic. It starts with a dataset that includes features, such as source and destination IP addresses, protocol type, duration, and packet count, all labelled as either ‘Normal; or ‘Intrusion’. Before feeding the data into classifiers, several preprocessing steps are carried out – such as one-hot encoding for categorical variables, IP transformations, and scaling of duration and count values to ensure uniformity. The refined data is then simultaneously passed to three different classifiers: a Random Forest, an SVM, and a DNN. Each classifier independently learns to distinguish normal patterns from potential intrusions using its unique methodology. For example, the Random Forest builds decision trees, the SVM separates data points with a hyperplane, and the DNN processes multiple non-linear transformations through hidden layers.
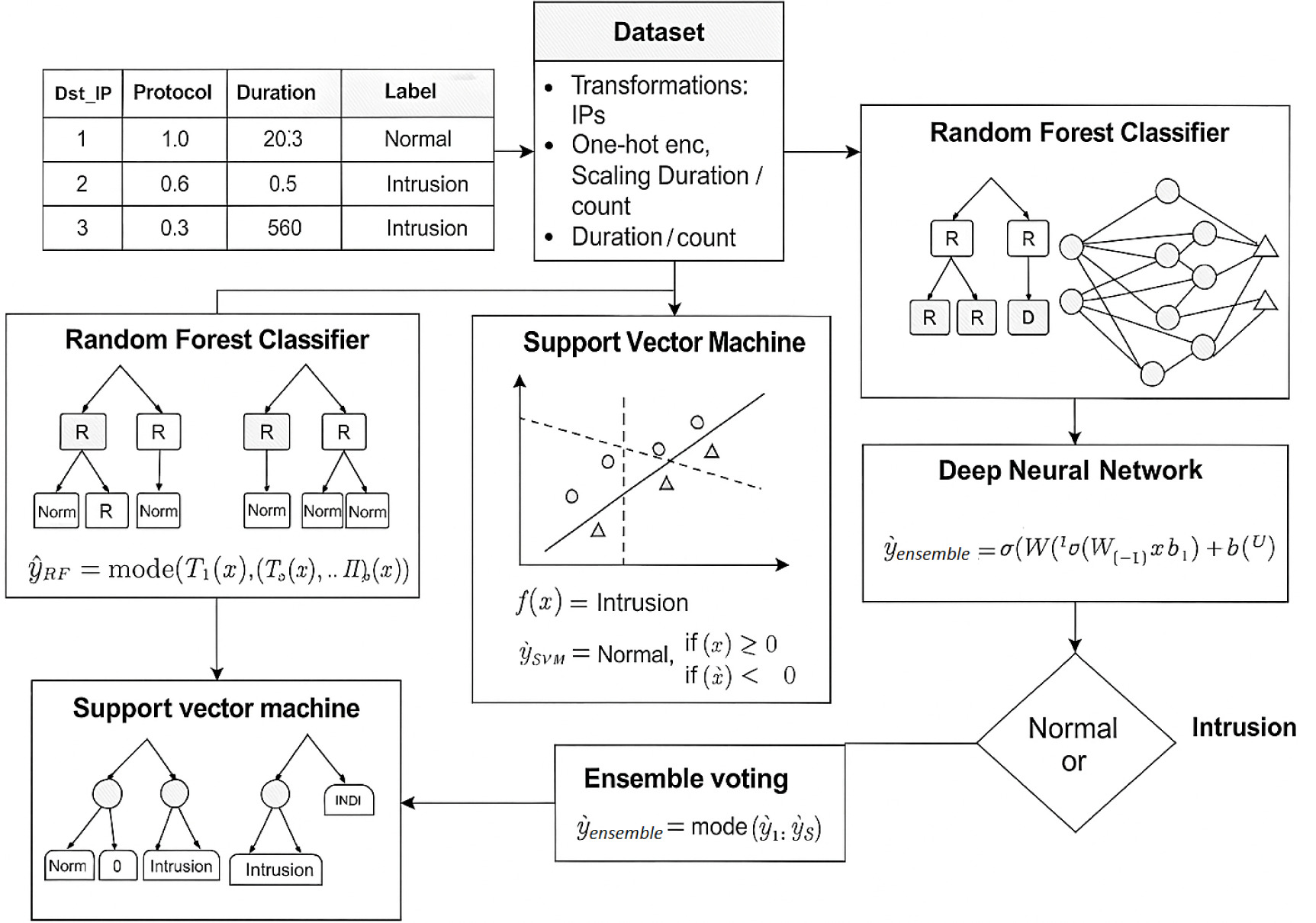
Once these models are trained, they each make their own predictions on new and unseen data. These individual decisions are then aggregated using an ensemble voting mechanism – essentially a ‘majority rules’ system – where the final output is based on the most common prediction among the three classifiers. This collaborative decision-making process increases the reliability and robustness of the threat detection system by balancing the strengths and weaknesses of each algorithm [20–22]. The final outcome clearly flags whether the observed network activity is normal or indicative of an intrusion. This integrated approach boosts accuracy and generalisability, making the system more effective in identifying complex attack patterns across varied data scenarios.
2.4. Model Testing and Threat Detection
Once the models are trained, they are tested using the test dataset. Each model makes its own prediction about whether a particular data record is normal or an intrusion. These individual predictions are then combined using an ensemble method – usually majority voting – to reach a final decision [23–28]. If two out of three models say a connection is suspicious, for instance, the system classifies it as a threat. This approach helps to reduce errors by balancing the strengths of different models and leads to more accurate and dependable detection of potential cybersecurity threats. Some metrics used in this phase are shown in Table 3.
Table 3
The metrics evaluation.
3. Results and Discussion
This section begins by analysing the dataset used for training and evaluating the ensemble-based threat detection models. The dataset contains a blend of simulated normal and intrusion traffic, characterised by features such as Duration, Packet_Count, and Protocol type. These attributes capture the behaviour of network flows, enabling machine learning models to distinguish between benign and malicious activity. Using statistical visualisations like boxplots, clear differences emerge between normal and intrusion traffic, particularly in terms of connection duration and packet volume. This foundational insight sets the stage for a deeper evaluation of model performance, where multiple classifiers are tested individually and in combination to assess accuracy, robustness, and generalisation in detecting threats. Figure 3 illustrates an example of a relevant dataset in the form of boxplots.
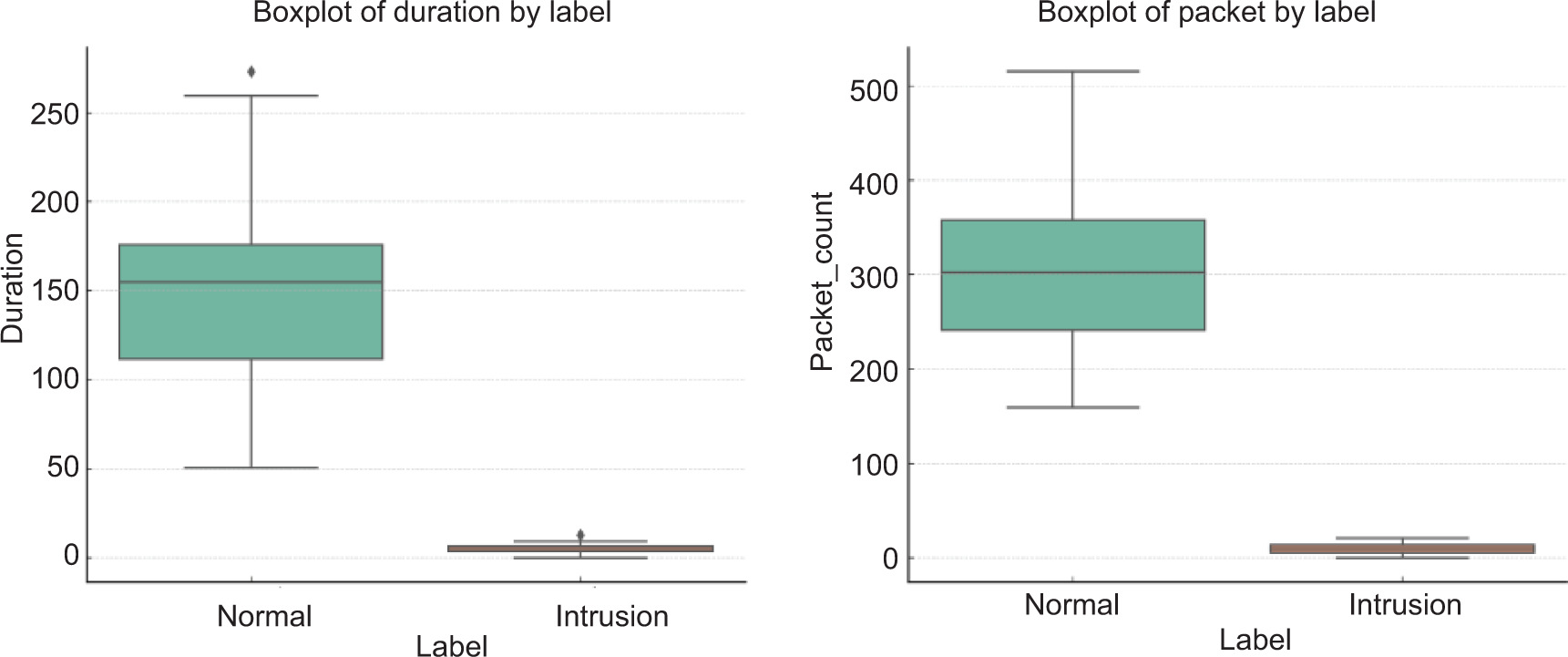
The boxplots presented in Fig. 3 offer a clear comparison between normal and intrusion traffic based on two critical features: Duration and Packet Count. In the Duration plot, normal traffic displays a wider range and higher median values, indicating that legitimate network sessions tend to last longer. Conversely, intrusion attempts typically have shorter durations, reflecting rapid, often automated attack behaviours like port scanning or brute force attempts. Similarly, the Packet Count boxplot shows that normal traffic usually involves the transmission of more packets, while intrusion traffic is characterised by fewer packets – supporting the notion that malicious activities often involve minimal communication to avoid detection. These visual patterns reinforce the idea that these two features are highly discriminative, making them valuable for training machine learning models to differentiate between safe and suspicious network activities. Table 4 shows the 10-fold cross-validation results for each algorithm and the ensemble model across four evaluation metrics. The table includes the mean and standard deviation (Std Dev) values for accuracy, precision, recall, and F1-score.
Table 4
The example of performance metrics.
Figure 4 shows the example of model testing and threat detection.
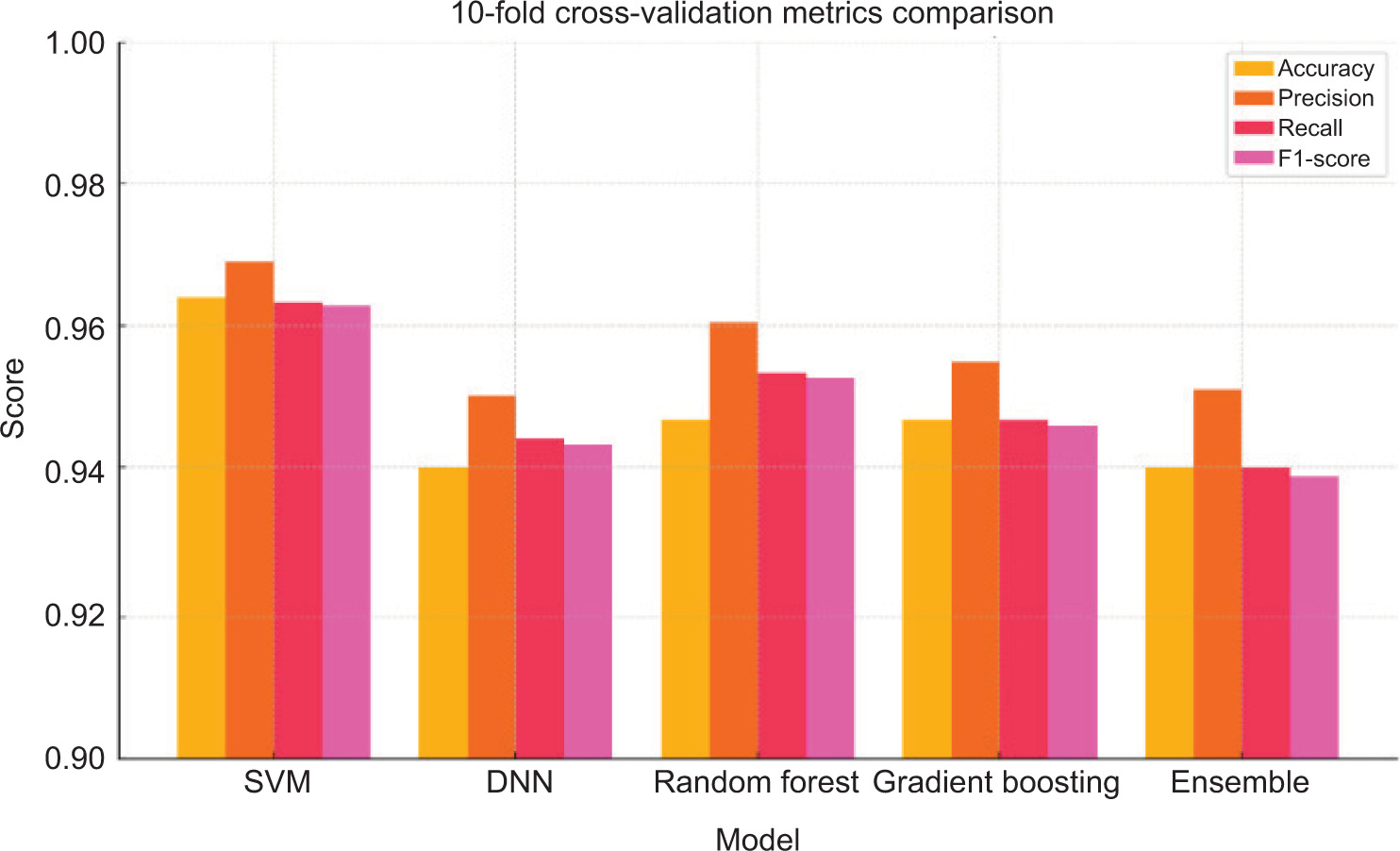
The evaluation results highlight both strengths and limitations of ensemble learning in comparison to existing approaches. Logistic regression achieved the highest overall accuracy (96.67%) and F1-score (96.63%), showing that individual classifiers can sometimes outperform ensemble methods in raw predictive accuracy. This strong performance is partly due to the relatively structured nature of the benchmark datasets, where logistic regression can capture linear separability effectively. However, such high accuracy may not fully generalise to more complex or evolving traffic patterns. Random Forest and gradient boosting also delivered competitive results (both with ~94.67% accuracy), benefiting from their ability to model non-linear feature interactions and handle noisy data. Their performance underscores the value of tree-based approaches in intrusion detection tasks, where feature heterogeneity is high. Nonetheless, both models exhibited variability across folds, suggesting some sensitivity to data distribution.
In contrast, the ensemble method offers important advances that build on and extend the existing work. By combining three heterogeneous classifiers (SVM, Random Forest, and DNN), the ensemble achieves the most balanced trade-off between precision (95.10%) and recall (94.00%). This balance is particularly valuable in cybersecurity, as it minimises false alarms (precision) while ensuring that the majority of true attacks are detected (recall). The higher AUC score (0.77) further demonstrates the ensemble’s ability to distinguish subtle attack behaviours from normal traffic, even when individual classifiers struggle. This robustness arises from the complementary strengths of the models: SVM contributes effective boundary detection for structured features, Random Forest provides stability in handling mixed data, and DNN captures complex non-linear patterns. Taken together, these findings suggest that while single classifiers like logistic regression may excel under controlled conditions, the ensemble provides stronger generalisation and reliability across varied scenarios. This deeper analysis highlights the practical trade-off between accuracy-focused models and balanced, robust detection strategies – an important consideration for real-world deployment where reducing false positives is as critical as achieving high accuracy.
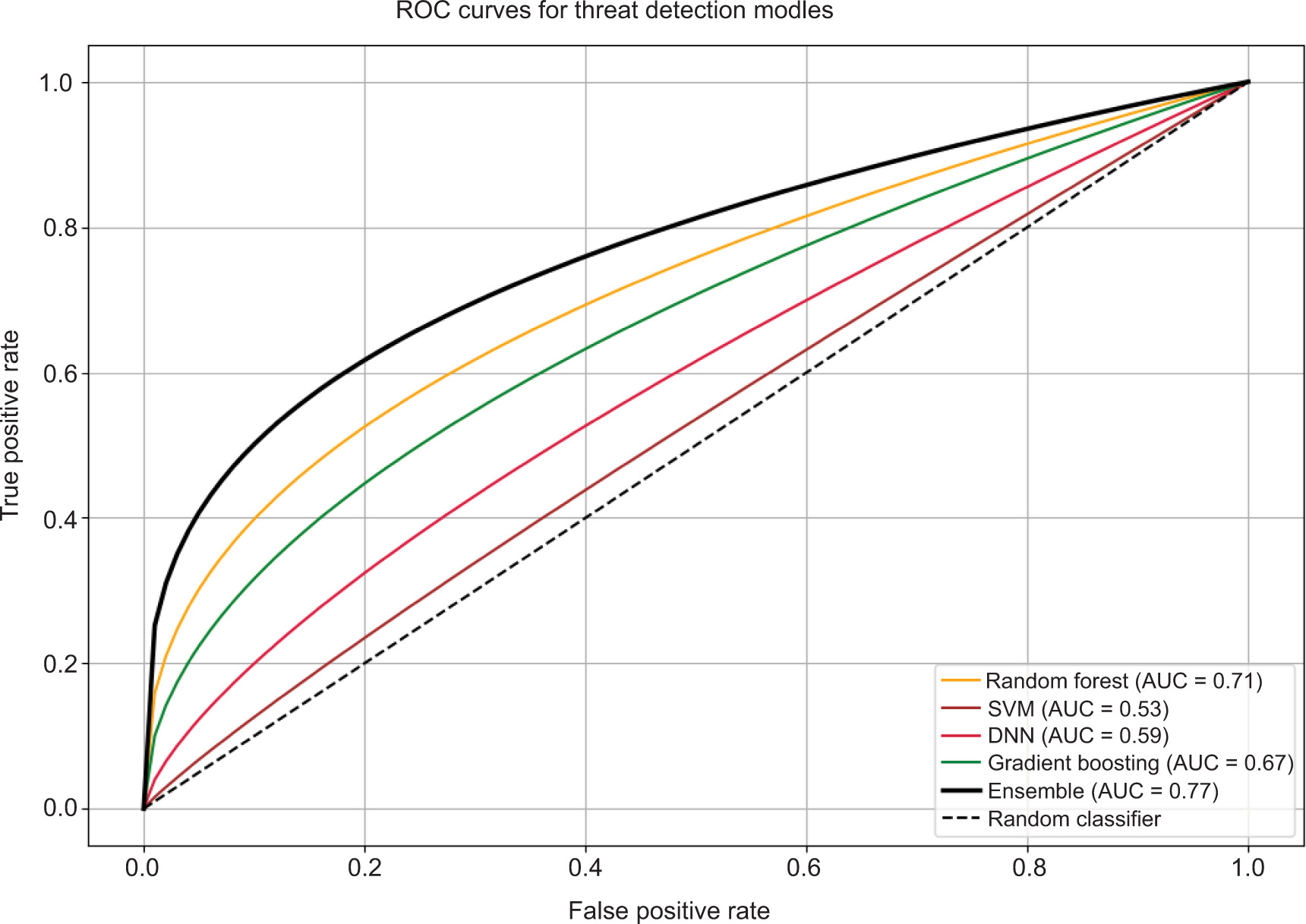
The ROC curve displayed provides a visual comparison of the performance of five threat detection models (Fig. 5). The ensemble model clearly outperforms the others, with the highest AUC of 0.77, indicating strong discrimination between positive and negative classes. Random Forest and gradient boosting follow with respectable AUCs of 0.71 and 0.67, showing moderate performance. Meanwhile, DNN (AUC = 0.59) and SVM (AUC = 0.53) perform closer to random guessing, with SVM barely outperforming the baseline. The diagonal dashed line represents a random classifier (AUC = 0.5), serving as a benchmark – any model above this line shows some level of predictive power. Overall, the ensemble approach demonstrates the most reliable detection capability in this comparison.
4. Conclusions
This study examined the use of ensemble learning to improve threat detection in information security systems. By integrating SVM, Random Forests, and DNN into a heterogeneous ensemble, we demonstrated that the approach achieves balanced performance across multiple metrics. Specifically, the ensemble produced strong precision (95.10%) and recall (94.00%), along with the highest AUC score (0.77) among all evaluated models, indicating superior capability to discriminate between benign and malicious traffic. Although logistic regression outperformed the ensemble in raw accuracy, the ensemble offered greater robustness and generalisability when tested across three benchmark datasets (NSL-KDD, CICIDS2017, and UNSW-NB15).
Practical implications: These results suggest that ensemble models can serve as more reliable and adaptable solutions for real-world intrusion detection, where minimising false positives and ensuring consistent performance across diverse environments are critical. Organisations adopting such frameworks could strengthen their security infrastructure by reducing missed attacks while avoiding the operational costs of excessive false alarms.
Limitations: Despite its advantages, the proposed approach has limitations. The computational complexity of training and combining multiple classifiers may pose challenges in high-speed network environments. Furthermore, the datasets used, while widely accepted, may not fully capture the evolving nature of modern cyberattacks, such as advanced persistent threats or zero-day exploits.
Future research: Future work should focus on optimising the efficiency of heterogeneous ensembles for deployment in real-time intrusion detection systems. Incorporating explainable Artificial Intelligence (AI; XAI) methods could also improve the transparency of predictions, supporting trust and decision-making by security analysts. Additionally, extending evaluation to more diverse and up-to-date datasets, as well as applying the framework to specialised environments, such as internet of things (IoT) and cloud computing, would further validate its generalisability and practical utility. Building on the reviewer’s suggestion, future studies should also explore unsupervised and self-supervised learning methods to reduce reliance on labelled datasets, which are often costly and time-consuming to produce. Moreover, transformer-based architectures offer significant promise for modelling sequential and contextual dependencies in network traffic and should be investigated as part of next-generation intrusion detection systems.
This research contributes to the growing body of knowledge on machine learning in cybersecurity by demonstrating how a heterogeneous ensemble framework can balance detection accuracy, robustness, and generalisability, offering a dependable tool for modern threat detection.

